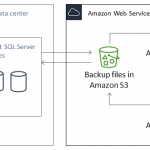
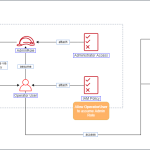
Được công ty công nghệ đa quốc gia Amazon ra mắt tại Mỹ vào ngày 14 tháng 3 năm 2006, Amazon S3 là một trong bộ ba dịch vụ lưu trữ đám mây tiện ích của Amazon Web Services, bao gồm Amazon S3, Amazon EBS và Amazon EFS.
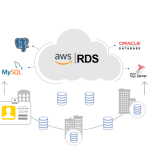
Amazon S3 hay còn có tên gọi đầy đủ là Amazon Simple Storage Service, là một dịch vụ lưu trữ đối tượng được cung cấp bởi Amazon Web Services (AWS). Với Amazon S3, người dùng có khả năng lưu trữ và quản lý dữ liệu đối tượng một cách đơn giản, hiệu quả trên Internet. Dịch vụ này cho phép người dùng lưu trữ bất kỳ loại dữ liệu nào, từ hình ảnh, video, tệp tin đến dữ liệu của ứng dụng, website, hoặc nguồn dữ liệu lớn (Big Data).

Amazon S3 cung cấp nhiều tính năng đa dạng như mở rộng dung lượng lưu trữ theo nhu cầu, đảm bảo tính khả dụng cao thông qua đa điểm lưu trữ, cùng với đó là các cơ chế bảo mật mạnh mẽ. Người dùng cũng có thể tận dụng các tính năng quản lý để tổ chức dữ liệu một cách hiệu quả, thiết lập quyền truy cập theo yêu cầu cụ thể của họ, và tuân thủ các tiêu chuẩn an ninh hoặc quy định nội bộ.
Hiện nay, Amazon S3 được dùng để phục vụ cho nhiều ngành công nghiệp và nhu cầu khác nhau như lưu trữ website, dữ liệu di động, ứng dụng doanh nghiệp, phân tích dữ liệu lớn, thiết bị Internet of Things (IoT), sao lưu dữ liệu,…
Các tầng lưu trữ của Amazon S3
Amazon S3 cung cấp ba tầng lưu trữ khác nhau để đáp ứng nhu cầu lưu trữ đa dạng của người dùng, bao gồm:
- Amazon S3 Standard: Đây là tầng lưu trữ phù hợp cho dữ liệu thường xuyên truy cập và cần có độ phân phối cao, độ trễ thấp cùng với thông lượng lớn. Tầng này đáp ứng cho các ứng dụng yêu cầu truy cập dữ liệu liên tục như các trang web động, phân phối nội dung và các khối lượng công việc lớn.
- Amazon S3 Infrequent Access: Cung cấp giá lưu trữ thấp hơn cho dữ liệu ít được truy cập, nhưng cần nhanh chóng truy cập được. Nó thích hợp để lưu trữ sao lưu, phục hồi thảm họa và lưu trữ dữ liệu dài hạn.
- Amazon Glacier: Đây là tầng lưu trữ ít tốn kém nhất trong Amazon S3, được thiết kế để lưu trữ dữ liệu lâu dài. Tầng này cung cấp tốc độ truy xuất trong khoảng từ vài phút đến vài giờ, chậm hơn hai tầng phía trên. Người dùng có thể sử dụng các chính sách quản lý vòng đời để quản lý dữ liệu, tự động di chuyển dữ liệu từ các tầng lưu trữ cao hơn xuống Glacier theo thời gian.

–
Các khái niệm cơ bản trong Amazon S3
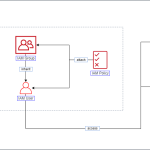
Bucket
Bucket hay vùng chứa trong Amazon S3 đại diện cho một không gian lưu trữ logic, là nơi chứa các đối tượng dữ liệu. Mỗi bucket tương ứng với một “thùng chứa” độc lập trên dịch vụ lưu trữ đám mây Amazon S3. Trên Amazon S3, dữ liệu được tổ chức thành các đối tượng. Mỗi object bao gồm dữ liệu thực sự cần lưu trữ (data) cùng với metadata, là các thông tin mô tả về dữ liệu đó. Tuy nhiên, một bucket có thể chứa nhiều object khác nhau, không giới hạn về số lượng.
Mục đích chính của việc sử dụng bucket trong Amazon S3 là:
- Tổ chức và phân loại dữ liệu: Bucket cung cấp một cấu trúc tổ chức để lưu trữ và phân chia dữ liệu vào các đơn vị rõ ràng. Việc phân tách dữ liệu vào các bucket riêng biệt giúp người dùng dễ dàng quản lý và tìm kiếm thông tin khi cần thiết.
- Quản lý quyền truy cập: Bucket cho phép người dùng xác định, quản lý quyền truy cập vào dữ liệu. Bằng cách thiết lập các chính sách và quyền hạn truy cập, người quản trị có thể kiểm soát ai có thể truy cập và thực hiện thao tác với dữ liệu trong từng bucket cụ thể.
- Định danh toàn cầu và xác định vị trí lưu trữ: Mỗi bucket được đặt tên duy nhất trên toàn bộ mạng lưới của Amazon S3, đồng thời người dùng có thể chọn khu vực lưu trữ rõ ràng cho bucket. Điều này giúp xác định nơi lưu trữ vật lý của dữ liệu, đảm bảo tính định danh cho mỗi không gian lưu trữ.
- Phục vụ cho mục đích báo cáo và quản lý: Các hoạt động và thông tin liên quan đến mỗi bucket đều được ghi lại, giúp tạo báo cáo về hoạt động, theo dõi tài nguyên và quản lý chi phí.

Object
Object hay còn gọi là đối tượng, đại diện cho một đơn vị dữ liệu lưu trữ cụ thể. Mỗi object bao gồm hai phần chính: object data (dữ liệu đối tượng) và metadata. Một object được xác định duy nhất trong một bucket bằng key (name) và version ID.
Dữ liệu đối tượng (object data) là nội dung thực tế cần lưu trữ, có thể là bất kỳ loại hình dữ liệu nào, ví dụ như các tệp tin, thông tin của ứng dụng,… Amazon S3 không giới hạn về loại hình dữ liệu được lưu trữ trong mỗi đối tượng, chỉ đơn thuần thực hiện chức năng lưu trữ mà không quan tâm đến loại hình hay nội dung cụ thể của dữ liệu.

Metadata là các thông tin mô tả về đối tượng, được lưu trữ dưới dạng cặp tên – giá trị (name – value). Những thông tin này bao gồm các chi tiết về đối tượng như loại hình dữ liệu, ngày chỉnh sửa gần nhất, kích thước, loại mã hóa (nếu có), cùng các thông tin khác giúp mô tả, quản lý đối tượng một cách chi tiết và hiệu quả. Metadata đóng vai trò quan trọng trong việc xác định, tìm kiếm và quản lý dữ liệu.
Key
Trong Amazon S3, key là một chuỗi định danh duy nhất và không thể thay đổi, tương ứng với mỗi object được lưu trữ trong một bucket cụ thể, giúp xác định vị trí chính xác của đối tượng trong cấu trúc lưu trữ của bucket.
Key thường được xem như một đường dẫn hoặc một địa chỉ trỏ đến đối tượng. Khi kết hợp với các thông tin khác như web service endpoint, tên bucket, version, key tạo thành một URL duy nhất để truy cập đến đối tượng cụ thể trong Amazon S3.
Region
Region (vùng) cho phép người dùng chọn khu vực địa lý cụ thể để lưu trữ bucket và dữ liệu của họ trên nền tảng lưu trữ đám mây của AWS. Việc lựa chọn vùng phù hợp mang lại nhiều lợi ích thiết thực như giảm độ trễ, tối ưu chi phí, cải thiện độ khả dụng và hiệu suất của dịch vụ.
Để có thể lựa chọn những khu vực mà Amazon S3 lưu trữ có hiệu quả, tối ưu nhất, người dùng cần cân nhắc đến 4 yếu tố quan trọng bao gồm giá cả, địa điểm khách hàng sử dụng dịch vụ, độ trễ và tính khả dụng dịch vụ.
Amazon S3 (Amazon Simple Storage Service) được thiết kế để cung cấp một quy trình hoạt động đơn giản và linh hoạt, giúp người dùng lưu trữ, truy xuất dữ liệu một cách hiệu quả. Quy trình hoạt động cơ bản của Amazon S3 bao gồm các bước chính sau:
Bước 1: Đăng nhập vào Amazon S3 và khởi tạo một bucket
Người dùng bắt đầu bằng việc đăng nhập vào tài khoản Amazon Web Services (AWS) và tạo một bucket, đây là không gian lưu trữ logic để tổ chức và lưu trữ dữ liệu của họ. Mỗi bucket có tên duy nhất trên toàn cầu và là nơi lưu trữ các đối tượng.
Bước 2: Thêm đối tượng vào bucket
Sau khi tạo bucket, người dùng có thể thêm các đối tượng (objects) vào bucket đó. Đối tượng có thể là bất kỳ loại dữ liệu nào như tệp tin, thông tin ứng dụng, hình ảnh, video, và dữ liệu khác. Việc thêm đối tượng vào bucket giúp người dùng tổ chức và lưu trữ dữ liệu theo cách linh hoạt.
–
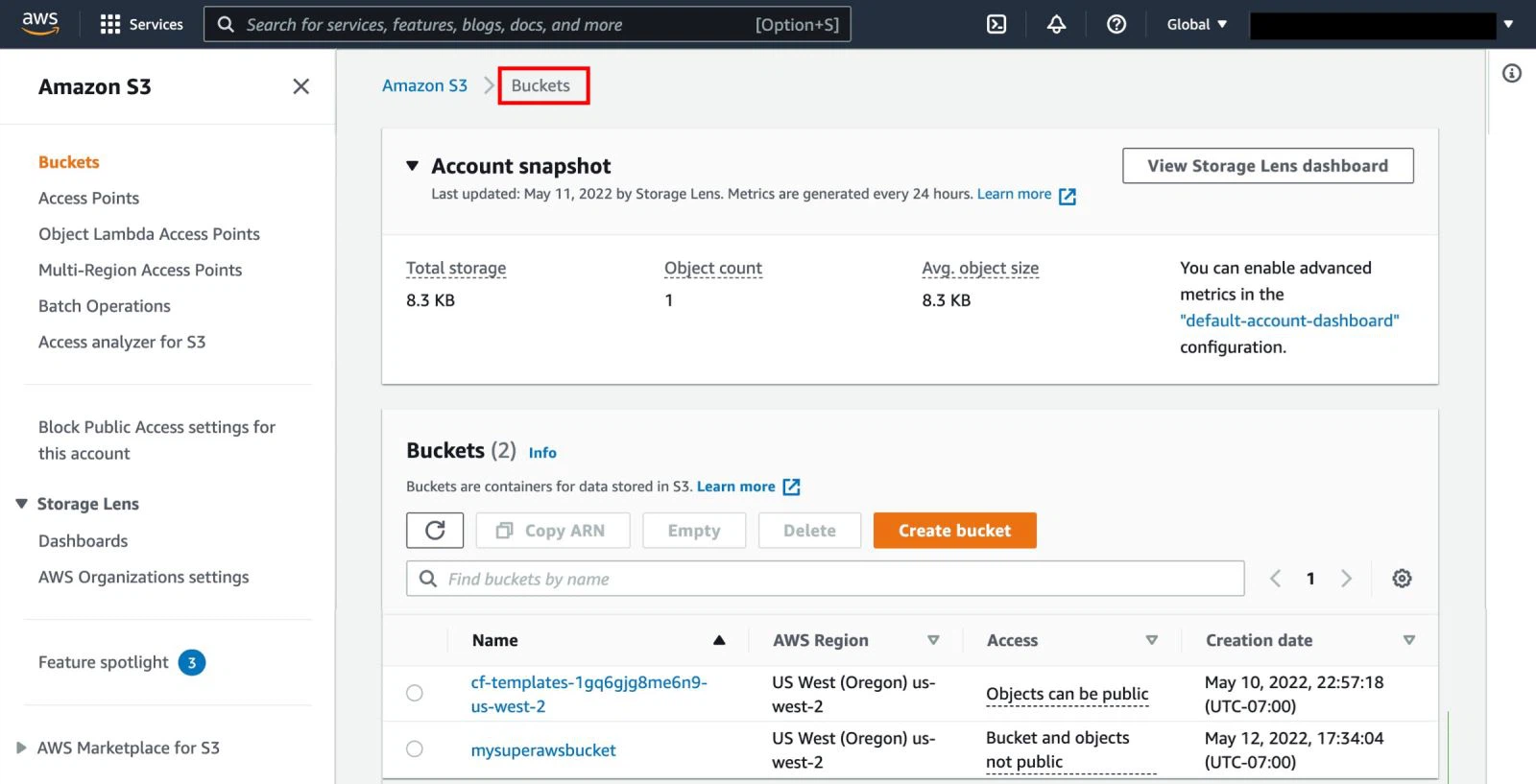
Bước 3: Xem thông tin về đối tượng
Người dùng có khả năng xem thông tin chi tiết về các đối tượng trong bucket, bao gồm metadata mô tả về dữ liệu và các thuộc tính khác nhau của đối tượng. Thông tin này cung cấp cái nhìn tổng quan về nội dung và thông tin mô tả của dữ liệu lưu trữ.
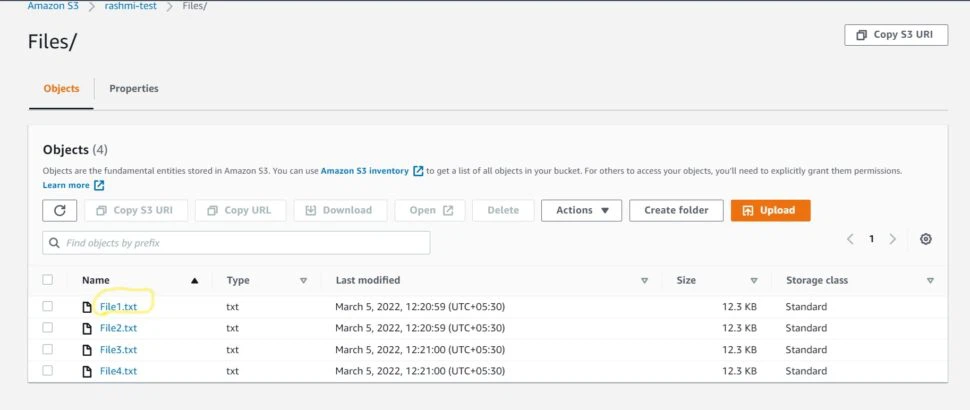
Bước 4: Thực hiện thao tác di chuyển, xóa đối tượng hoặc bucket nếu cần thiết
Amazon S3 cung cấp khả năng di chuyển, xóa đối tượng và bucket một cách dễ dàng. Người dùng có thể di chuyển hoặc xóa đối tượng, bucket mà không ảnh hưởng đến dữ liệu khác, cũng như có thể thực hiện các thao tác quản lý để tổ chức dữ liệu hiệu quả hơn.
–
Các tính năng vượt trội của Amazon S3
Amazon S3 được thiết kế có những tính năng tối giản, hỗ trợ quá trình sử dụng của người dùng:
- Lưu trữ đa dạng và không giới hạn: Cho phép lưu trữ đa dạng các loại dữ liệu trong các bucket với dung lượng tối đa 5TB cho mỗi đối tượng.
- Quản lý dữ liệu linh hoạt: Người dùng có thể tải và chia sẻ dữ liệu từ các bucket một cách dễ dàng.
- Phân quyền và bảo mật: Có khả năng quản lý phân quyền cho phép hay từ chối quyền truy cập đối với dữ liệu trong bucket. Cung cấp các tùy chọn mã hóa dữ liệu ở cả client side và server side.
- Giao diện tương tác tiêu chuẩn: Sử dụng REST hoặc SOAP để tương tác thông qua các công cụ lập trình.
- Tính ổn định: Cam kết SLA 99.99% uptime, hỗ trợ khôi phục dữ liệu trong trường hợp lỗi và lưu trữ nhiều bản sao của dữ liệu.
- Đơn giản và dễ sử dụng: Xây dựng trên các khái niệm cơ bản và có khả năng tương thích với mọi ứng dụng của người dùng. Tuy nhiên, Amazon S3 vẫn hỗ trợ thiết kế lưu trữ phức tạp khi cần thiết.
- Tính mở rộng: Tự động mở rộng khi có lưu lượng truy cập gia tăng, giúp người dùng tối ưu hóa và chỉ trả phí cho dung lượng thực sự sử dụng.
- Chi phí tối thiểu: Cung cấp giá cả cạnh tranh và mức phí thấp hơn so với các giải pháp tương tự trên thị trường.
Với những tính năng nổi trội, khi sử dụng Amazon S3 sẽ mang đến cho bạn nhiều lợi ích bất ngờ:
- Hiệu suất và độ bền vượt trội: S3 cung cấp hiệu suất cao, linh động, sẵn sàng để được sử dụng liên tục. Thời gian uptime lên đến 99.9%, giúp người dùng dễ dàng điều chỉnh quy mô lưu trữ theo nhu cầu, mà không cần trả trước hay mua theo chu kỳ.
- Tiết kiệm chi phí thông qua lớp lưu trữ: Sử dụng các lớp lưu trữ S3 giúp người dùng quản lý chi phí hiệu quả hơn. Phân tích lớp lưu trữ S3 giúp xác định và di chuyển dữ liệu sang các lớp lưu trữ có chi phí thấp hơn, hỗ trợ việc tối thiểu chi phí mà vẫn duy trì được hiệu suất.
- Bảo mật an toàn, chặt ché: Amazon S3 tích hợp nhiều tính năng bảo mật để ngăn chặn truy cập trái phép, bao gồm việc mã hóa dữ liệu, tuân thủ các tiêu chuẩn bảo mật như PCI-DSS, FedRAMP, FISMA. Amazon S3 có khả năng kiểm tra giúp giám sát chặt chẽ các hoạt động truy cập vào ứng dụng.
- Quản lý dữ liệu hiệu quả: S3 cung cấp các công cụ giúp phân loại, quản lý và báo cáo về dữ liệu. Việc phân tích các lớp lưu trữ, áp dụng chính sách Vòng Đời S3, sao chép liên khu vực và quản lý khóa đối tượng giúp người dùng kiểm soát chi tiết hơn về dữ liệu của họ.
- Truy vấn và phân tích dữ liệu linh hoạt: S3 cung cấp dịch vụ truy vấn tại chỗ, tính năng Amazon Redshift Spectrum cho phép người dùng trực tiếp phân tích dữ liệu lưu trữ trên S3 mà không cần di chuyển dữ liệu.
- Hỗ trợ đa dạng từ mạng lưới đối tác AWS (APN): Amazon S3 kết hợp với APN, giúp người dùng lưu trữ và bảo vệ dữ liệu một cách hiệu quả. Từ việc nhận diện đối tác có thể di chuyển dữ liệu, đến việc mua giải pháp tích hợp trên AWS Marketplace, người dùng có thêm nhiều sự lựa chọn và hỗ trợ đa dạng khi sử dụng Amazon S3.
Trong thời đại công nghệ 4.0, nhu cầu lưu trữ dữ liệu của các doanh nghiệp ngày càng tăng cao, và với giải pháp điện toán đám mây AWS cung cấp dịch vụ lưu trữ đơn giản là Amazon S3, doanh nghiệp có thể giải quyết nhanh chóng vấn đề lưu trữ thông tin, tập trung nguồn lực vào phát triển kinh doanh. Hy vọng rằng qua bài viết trên, mọi người sẽ có thêm nhiều thông tin hữu ích!
Vina Aspire là công ty tư vấn, cung cấp các giải pháp, dịch vụ CNTT, An ninh mạng, bảo mật & an toàn thông tin tại Việt Nam. Đội ngũ của Vina Aspire gồm những chuyên gia, cộng tác viên giỏi, có trình độ, kinh nghiệm và uy tín cùng các nhà đầu tư, đối tác lớn trong và ngoài nước chung tay xây dựng.
Các Doanh nghiệp, tổ chức có nhu cầu liên hệ Công ty Vina Aspire theo thông tin sau:
Email: info@vina-aspire.com | Website: www.vina-aspire.com
Tel: +84 9024 17606 | Fax: +84 28 3535 0668
![]()
Vina Aspire – Vững bảo mật, trọn niềm tin