Ngày nay, doanh nghiệp ngày càng ứng dụng thường xuyên và mạnh mẽ các dịch vụ Amazon Web Services trong quá trình chuyển đổi số trong kinh doanh. Trong đó, AWS Redshift chính là một dịch vụ hỗ trợ các doanh nghiệp trong quá trình lưu trữ các dữ liệu theo quy mô hàng petabyte cực kỳ nhanh chóng và mạnh mẽ.
Trong bài viết này, doanh nghiệp hãy cùng Vina Aspire tìm hiểu về khái niệm AWS Redshift là gì, kiến trúc, các tính năng cũng như lợi ích nổi bật của giải pháp này nhé!
AWS Redshift là dịch vụ hỗ trợ doanh nghiệp lưu trữ các dữ liệu theo quy mô hàng petabyte vô cùng nhanh chóng và mạnh mẽ. AWS Redshift được xây dựng dựa trên trên PostgreSQL, tuy nhiên, dịch vụ này không được dùng trong OLTP (hay On-line transactional processing – một hệ thống xử lý giao dịch trực tuyến) mà được triển khai trong OLAP (hay On-line analytical processing – một hệ thống xử lý phân tích trực tuyến). AWS Redshift sở hữu một số đặc điểm nổi bật sau mà doanh nghiệp cần lưu ý khi triển khai:

- Đây là dịch vụ tính tiền theo giờ vận hành dựa trên các instance mà doanh nghiệp đã lựa chọn sử dụng.
- Redshift AWS có hiệu suất mạnh mẽ gấp 10 lần so với những kho dữ liệu (hay data warehouse) khác.
- Hệ thống tiến hành lưu trữ các dữ liệu dưới dạng cột (hay column).
- Hỗ trợ doanh nghiệp SQL interface để thiết lập nên các query truy vấn.
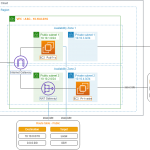
Sau khi đã hiểu khái niệm Amazon Redshift là gì, trong phần tiếp theo, doanh nghiệp hãy cùng Vina Aspire phân tích chi tiết về kiến trúc của AWS Redshift bao gồm những thành phần cùng những yếu tố gì nhé!
–
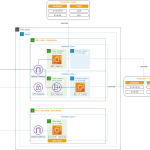
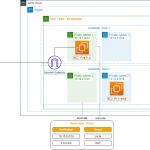
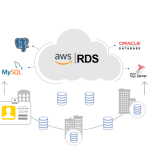
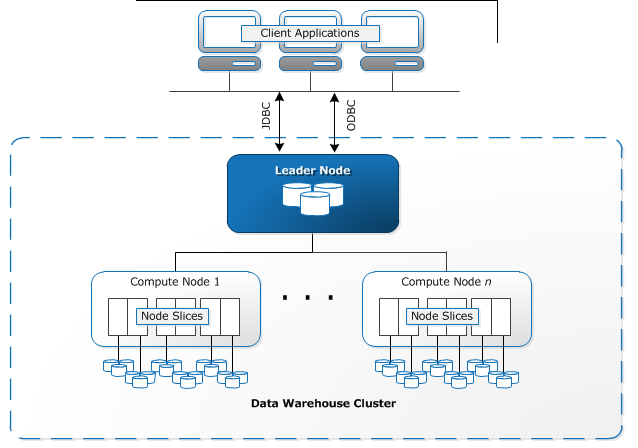
- Cluster: Đây chính là thành phần cốt lõi bên trong kiến trúc của AWS Redshift. Mỗi cluster sẽ bao gồm một hoặc rất nhiều nodes với nhiệm vụ thực hiện các công việc tính toán. Bên cạnh đó, trong từng cluster sẽ bao gồm một hoặc rất nhiều cơ sở dữ liệu database.
- Leader node: Có vai trò xử lý việc giao tiếp với những layer bên ngoài, chẳng hạn như triển khai các query và tổng hợp kết quả.
- Compute node: Có nhiệm vụ thực thi những câu truy vấn, sau đó, tiến hành gửi trả lại các kết quả cho leader node.
- Node slices: Mỗi compute node sẽ tiếp tục được phân chia nhỏ thành những node slice khác nhau. Từng node slice lại được chia đều các CPU, memory cũng như storage từ compute node này.
- Redshift spectrum: Đây chính là thành phần có nhiệm vụ truy vấn các dữ liệu một cách trực tiếp đến Amazon S3 mà không cần phải truyền tải các dữ liệu này vào những bảng của AWS Redshift.
- Một số thành phần khác: Security VPC/IAM/KMS, backup & restore, monitoring,…
Các tính năng và lợi ích nổi bật của AWS Redshift
KHẢ NĂNG QUẢN LÝ CHUYÊN SÂU
Khả năng quản lý chuyên sâu của AWS Redshift tập trung vào quá trình chuyển đổi từ các dữ liệu sang những thông tin chuyên sâu một cách nhanh chóng và đảm bảo mang đến cho doanh nghiệp hiệu quả về các hoạt động kinh doanh mà không cần cần lo lắng các hoạt động quản lý kho dữ liệu.
Amazon Redshift ServerlessAmazon Redshift Serverless chính là một lựa chọn phi máy chủ của AWS Redshift, giúp doanh nghiệp dễ dàng vận hành và tùy chỉnh quy mô phân tích chỉ trong vòng vài giây mà không cần phải lo lắng về việc thiết lập và quản lý các cơ sở hạ tầng kho dữ liệu. Với tính năng AWS Redshift Serverless, bất cứ người dùng nào, bao gồm những nhà phân tích dữ liệu, các chuyên gia phát triển, chuyên gia kinh doanh và những nhà khoa học nghiên cứu dữ liệu, đều có thể dễ dàng thu thập các thông tin chuyên sâu từ chính những dữ liệu này khi chỉ cần truyền tải và truy vấn các dữ liệu bên trong kho dữ liệu.
Trình soạn thảo các truy vấn phiên bản 2.0
Khi triển khai SQL, doanh nghiệp có thể giúp các chuyên gia phân tích dữ liệu, kỹ sư về dữ liệu cùng những người sử dụng SQL khác có thể dễ dàng tiếp cận các dữ liệu và hồ dữ liệu AWS Redshift của chúng ta hơn so với những khu vực làm việc trên trang web dành cho hoạt động nghiên cứu và phân tích dữ liệu.

–
Lúc này, trình soạn thảo truy các vấn phiên bản 2.0 sẽ giúp doanh nghiệp trực quan hóa những kết quả truy vấn cực kỳ đơn giản chỉ với một thao tác nhấp chuột. Từ đó, chúng ta sẽ xây dựng được các lược đồ và bảng biểu, đồng thời, truyền tải dữ các liệu một cách trực quan hóa và duyệt tìm các đối tượng của những cơ sở dữ liệu nhanh chóng và dễ dàng. Tính năng này cũng mang đến cho doanh nghiệp một trình soạn thảo thân thiện, trực quan nhằm thiết lập và chia sẻ những truy vấn SQL, các hoạt động phân tích, những kết quả và chú thích trực quan, đồng thời, quá trình chia sẻ cũng đảm bảo an toàn bảo mật.
Tự động thiết kế bảng
AWS Redshift còn giúp doanh nghiệp theo dõi các khối lượng công việc và tận dụng các thuật toán phức tạp cho nhằm tìm ra phương pháp cải thiện bố cục vật lý của các dữ liệu để từ đó, tối ưu hóa được tốc độ của các truy vấn. Khả năng tối ưu hóa bảng trong Redshift AWS sẽ tự động lựa chọn các khóa, tiến hành sắp xếp và phân phối sao cho hiệu quả để có thể tối ưu hóa về mặt hiệu năng cho khối lượng các công việc trong cụm.
Nếu AWS Redshift xác định quá trình ứng dụng khóa sẽ cải thiện, nâng cao hiệu năng của cụm thì các bảng sẽ được tự động thiết kế, thay đổi mà không cần đến sự can thiệp trực tiếp của đội ngũ quản trị viên. Một số tính năng bổ sung, chẳng hạn như: xóa bỏ chân không tự động, sắp xếp các bảng tự động và phân tích tự động sẽ giúp doanh nghiệp loại bỏ các nhu cầu bảo trì và tùy chỉnh theo dạng thủ công đối với các cụm AWS Redshift. Nhờ đó, doanh nghiệp sẽ đạt được mức hiệu năng tốt nhất đối với những cụm cùng khối lượng các công việc sản xuất mới.
Truy vấn thông qua công cụ của riêng doanh nghiệp
AWS Redshift mang đến cho doanh nghiệp sự linh hoạt để vận hành các truy vấn bên trong bảng điều khiển hệ thống hoặc triển khai kết nối với các công cụ máy khác, bao gồm: SQL, thư viện, một số công cụ khoa học dữ liệu như AWS Quicksight, Power BI, Tableau, QueryBook, Jupyter Notebook,…
Kết nối API đơn giản cho việc tương tác với AWS Redshift
AWS Redshift giúp doanh nghiệp dễ dàng truy cập các dữ liệu với toàn bộ những loại ứng dụng khác nhau theo sự kiện và các ứng dụng dựa vào dịch vụ trang web phi máy chủ, dù chúng là dạng truyền thống, dạng nằm trong bộ chứa hay dạng đang hoạt động trên đám mây. Kết nối API cho các dữ liệu của AWS Redshift sẽ đơn giản hóa quá trình truy cập, thu thập và truy xuất dữ liệu từ những ngôn ngữ lập trình cùng các nền tảng được AWS SDK hỗ trợ, chẳng hạn như Java, Python, Node.js, C ++, PHP, Ruby và Go.
Kết nối API các dữ liệu sẽ loại bỏ nhu cầu của doanh nghiệp về cấu hình trình điều khiển cũng như quản lý kết nối với các cơ sở dữ liệu. Thay vào đó, chúng ta có thể triển khai các lệnh SQL đến cụm AWS Redshift một cách đơn giản nhờ vào việc gọi điểm cuối kết nối API bảo mật do kết nối API các dữ liệu cung cấp. Kết nối API các dữ liệu sẽ quản lý những kết nối về dữ liệu đệm và cơ sở dữ liệu. Kết nối API các dữ liệu không đồng bộ, chính vì vậy, doanh nghiệp có thể truy xuất những kết quả về sau này và kết quả truy vấn có thể được hệ thống lưu trữ trong vòng 24 giờ.
Khả năng chịu lỗi
AWS Redshift sở hữu đa dạng tính năng hỗ trợ doanh nghiệp cải thiện, nâng cao độ tin cậy cho cụm kho dữ liệu của chúng ta. Chẳng hạn: AWS Redshift liên tục quản lý, theo dõi về tình trạng của cụm và tiến hành tự động sao chép những dữ liệu từ các ổ đĩa đã bị hỏng, sau đó, hệ thống sẽ thay thế nút khi cần nhằm đảm bảo được khả năng chịu lỗi. Các cụm này cũng có thể được hệ thống chuyển đến những vùng sẵn sàng (hay AZ) thay thế mà không làm thất lạc các dữ liệu hoặc làm thay đổi ứng dụng.
PHÂN TÍCH TẤT CẢ DỮ LIỆU
AWS Redshift sở hữu đầy đủ thông tin chuyên sâu được tích hợp theo đúng thời gian thực và các nội dung được phân tích cũng mang tính dự đoán về những dữ liệu phức tạp, có quy mô lớn của doanh nghiệp bên trong các cơ sở dữ liệu, các hồ dữ liệu, các kho dữ liệu cũng như hàng nghìn các bộ dữ liệu của những bên thứ ba khác.
Truy vấn các liên kết
Tính năng truy vấn các liên kết mới bên trong AWS Redshift giúp doanh nghiệp truy cập vào các cơ sở dữ liệu quan hệ dành cho những hoạt động của mình. Chúng ta có thể truy vấn các dữ liệu một cách trực tiếp trên một hoặc trên nhiều cơ sở dữ liệu AWS Relational Database Service (hay AWS RDS) cùng Aurora PostgreSQL và cơ sở dữ liệu RDS MySQL cùng Aurora MySQL nhằm quan sát đầy đủ và ngay lập tức những hoạt động kinh doanh mà không cần phải tiến hành di chuyển các dữ liệu.
Doanh nghiệp có thể kết nối các dữ liệu từ chính kho dữ liệu AWS Redshift, các dữ liệu bên trong hồ dữ liệu cũng như các dữ liệu trong nhiều kho lưu trữ hoạt động khác nhau của chúng ta để đưa ra các quyết định đúng đắn, chính xác hơn nhờ dựa vào các dữ liệu này. AWS Redshift cũng mang đến cho doanh nghiệp nhiều giải pháp tối ưu hóa cực kỳ tinh vi, giúp giảm thiểu việc di chuyển các dữ liệu thông qua kết mạng. Ngoài ra, giải pháp cũng hỗ trợ việc xử lý các dữ liệu song song một cách hàng loạt nhằm đảm bảo các truy vấn đạt được hiệu năng cao.
Truy vấn và truy xuất dữ liệu đến – đi từ hồ dữ liệu
Kho dữ liệu đám mây của AWS Redshift có thể giúp doanh nghiệp triển khai cả tính năng truy vấn các dữ liệu lẫn tính năng ghi các dữ liệu trở lại hồ dữ liệu tại những định dạng với khả năng mở tệp dễ dàng. Doanh nghiệp có thể truy vấn những định dạng tệp mở, bao gồm ORC, Parquet, JSON, CSV, Avro,… trong Amazon S3 nhờ vào việc triển khai SQL ANSI. Để truy xuất các dữ liệu sang hồ dữ liệu, chúng ta chỉ cần dùng câu lệnh UNLOAD của AWS Redshift bên trong dòng code SQL và chỉ định định dạng tệp là Parquet.
–
Sau đó, AWS Redshift sẽ xử lý tự động quá trình định dạng các dữ liệu và di chuyển chúng vào Amazon S3. Nhờ đó, doanh nghiệp có thể dễ dàng lưu trữ các dữ liệu với một cấu trúc được tổ chức khoa học, thường xuyên có thể được truy cập lẫn các dữ liệu với cấu trúc chưa được hoàn chỉnh bên trong kho dữ liệu của AWS Redshift. Song song đó, chúng ta cũng theo kịp hàng exabyte các dữ liệu có cấu trúc xác định, các dữ liệu với cấu trúc chưa hoàn chỉnh cũng như các dữ liệu không có cấu trúc bên trong Amazon S3. Việc truy xuất dữ liệu từ AWS Redshift quay trở lại hồ dữ liệu của doanh nghiệp sẽ giúp chúng ta phân tích dữ liệu một cách chuyên sâu hơn với nhiều dịch vụ Amazon Web Services như Amazon EMR, Amazon Athena và Amazon SageMaker.
Những tích hợp dịch vụ Amazon Web Services
AWS Redshift tích hợp cực kỳ mạnh mẽ với các dịch vụ Amazon Web Services, những cơ sở dữ liệu cùng các dịch vụ máy học, giúp doanh nghiệp xử lý các quy trình phân tích một cách hoàn chỉnh và dễ dàng hơn mà không gặp phải khó khăn, khúc mắc nào. Sau đây là một số ví dụ cụ thể về những tích hợp dịch vụ AWS của AWS Redshift:
- Amazon Lake Formation là dịch vụ giúp doanh nghiệp dễ dàng thiết lập hồ dữ liệu cho AWS Redshift đảm bảo an toàn chỉ trong vài ngày.
- Doanh nghiệp có thể tận dụng khả năng trích xuất, chuyển đổi và tải các dữ liệu (còn gọi là quy trình ETL) của AWS Glue vào AWS Redshift.
- Amazon Kinesis Data Firehose cung cấp cho doanh nghiệp phương thức dễ dàng nhất để có thể nắm bắt, chuyển đổi và tải các dữ liệu và truyền vào AWS Redshift để tiến hành các phân tích gần nhất với thời gian thực.
- Doanh nghiệp có thể tận dụng Amazon EMR cho việc xử lý các dữ liệu thông qua Hadoop/Spark và truyền tải kết quả vào AWS Redshift để hỗ trợ cho BI và phân tích.
- Amazon QuickSight chính là dịch vụ BI đầu tiên sở hữu mức giá thanh toán theo mỗi phiên sử dụng của doanh nghiệp để thiết lập các bảng báo cáo, tạo nên nhiều hình ảnh mang tính trực quan hóa cũng như các bảng thông tin trong các dữ liệu của hệ thống AWS Redshift.
- Doanh nghiệp có thể tận dụng Redshift AWS để chuẩn bị các dữ liệu vận hành cho những khối lượng công việc về máy học với Amazon SageMaker.
- Amazon Schema Conversion tool cùng AWS Database Migration Service (hay DMS) sẽ giúp doanh nghiệp gia tăng tốc độ di chuyển sang hệ thống AWS Redshift.
- Doanh nghiệp có thể tận dụng các hàm do người dùng xác định (hay UDF) bên trong AWS Lambda để gọi được một hàm Lambda từ những truy vấn SQL, tương tự như lúc chúng ta gọi các UDF bên trong AWS Redshift.
- AWS Redshift cũng được xây dựng tích hợp mạnh mẽ với Amazon Key Management Service (hay KMS) cũng như Amazon CloudWatch nhằm gia tăng tính bảo mật, khả năng theo dõi và tuân thủ các quy định.
- Doanh nghiệp có thể ghi UDF trong AWS Lambda để tích hợp với những dịch vụ của Amazon Web Services và truy cập vào những dịch vụ phổ biến, chẳng hạn như Amazon DynamoDB, Amazon SageMaker,…
Tích hợp với bảng điều khiển các đối tác
Doanh nghiệp có thể thúc đẩy nhanh chóng quá trình triển khai các dữ liệu và xây dựng nên các thông tin chi tiết với giá trị hữu ích về chúng ta chỉ trong vòng vài phút nhờ vào việc tích hợp với một số giải pháp của các đối tác bên trong bảng điều khiển của AWS Redshift. Sau đó, doanh nghiệp có thể đưa các dữ liệu từ nhiều ứng dụng bên thứ ba khác nhau như Google Analytics, Salesforce, Facebook Ads, Slack, Splunk, Jira, Marketo,… vào trong kho dữ liệu AWS Redshift của mình một cách hợp lý và hiệu quả nhất. Không những vậy, tính năng này cũng giúp doanh nghiệp có thể kết hợp những bộ dữ liệu khác biệt này với nhau và tiến hành phân tích chúng cùng nhau để tạo nên nhiều thông tin mang tính chuyên sâu hữu ích.
Chia sẻ các dữ liệu
Tính năng chia sẻ các dữ liệu trong AWS Redshift cho phép doanh nghiệp có thể nâng cao mức độ dễ dàng sử dụng, gia tăng hiệu năng và các lợi ích về chi phí khi chúng ta triển khai từ một đến nhiều cụm mà vẫn có khả năng chia sẻ được các dữ liệu. Hoạt động chia sẻ các dữ liệu này hỗ trợ người dùng truy cập dữ liệu ngay lập tức, đảm bảo đầy đủ chi tiết và cực kỳ nhanh chóng trên các cụm Redshift AWS mà không cần phải thực hiện thao tác sao chép hoặc di chuyển.
–
Tính năng chia sẻ các dữ liệu còn cho phép khả năng truy cập một cách trực tiếp vào các dữ liệu, giúp người dùng luôn thấy được các thông tin mới nhất ngay khi chúng ta cập nhật chúng trong kho dữ liệu và đảm bảo các thông tin này luôn nhất quán. Doanh nghiệp có thể chia sẻ các dữ liệu này trực tiếp một cách bảo mật an toàn với các cụm AWS Redshift trong cùng hoặc khác tài khoản Amazon Web Services cũng như trên khắp các khu vực khác nhau.
Giải pháp Amazon Data Exchange dành cho AWS Redshift
Doanh nghiệp có thể truy vấn những bộ dữ liệu AWS Redshift từ cụm Redshift của riêng mình mà không cần phải trải qua quá trình trích xuất, chuyển đổi và tải (hay ETL) các dữ liệu. Chúng ta có thể đăng ký để sử dụng những sản phẩm kho dữ liệu trên đám mây Redshift bên trong Amazon Data Exchange.
Mỗi khi có các cập nhật từ phía nhà cung cấp, khách đăng ký sẽ ngay lập tức thấy được những sự thay đổi đó. Nếu doanh nghiệp là nhà cung cấp các dữ liệu, hệ thống sẽ tự động cấp quyền truy cập khi gói đăng ký chính thức bắt đầu và sẽ thu hồi các quyền này khi gói đăng ký đã kết thúc. Sau đó, hóa đơn cũng sẽ được tạo tự động mỗi khi đến kỳ hạn thanh toán, còn những khoản thanh toán sẽ được thu thông qua hệ thống Amazon Web Services. Doanh nghiệp có thể cấp quyền truy cập vào những tệp phẳng, các dữ liệu bên trong AWS Redshift cũng như những dữ liệu được phân phối thông qua các kết nối API chỉ với duy nhất một gói đăng ký dịch vụ này.
Redshift ML
Redshift ML có nhiệm vụ giúp những nhà phân tích về dữ liệu, các nhà khoa học nghiên cứu các dữ liệu, chuyên gia BI cũng như nhà phát triển có thể dễ dàng xây dựng, đào tạo và triển khai các mô hình Amazon SageMaker thông qua SQL. Nhờ có Redshift ML, doanh nghiệp có thể triển khai các lệnh SQL để xây dựng và đào tạo nhiều mô hình Amazon SageMaker trên các dữ liệu của mình bên trong AWS Redshift. Sau đó, chúng ta sẽ sử dụng những mô hình này dành cho các kế hoạch dự đoán, chẳng hạn như: phát hiện sự thất thoát, dự báo tài chính, tối ưu cá nhân hóa và chấm điểm các rủi ro trong những truy vấn cùng các báo cáo của mình.
Hỗ trợ gốc dành cho các phân tích nâng cao
AWS Redshift hỗ trợ những dạng dữ liệu vô hướng tiêu chuẩn, bao gồm VARCHAR, NUMBER và DATETIME. Đồng thời, giải pháp này cũng hỗ trợ gốc dành cho các hoạt động và quy trình xử lý các phân tích nâng cao, chuyên sâu sau đây:
- Xử lý các dữ liệu không gian
AWS Redshift cung cấp cho doanh nghiệp dạng dữ liệu đa hình (hay GEOMETRY), hỗ trợ đa dạng các hình dạng hình học, chẳng hạn như Polygon, Point và Linestring. AWS Redshift cũng mang đến cho chúng ta các hàm SQL không gian hỗ trợ quá trình xây dựng những hình dạng hình học, xuất – nhập, hoạt động truy cập và xử lý các dữ liệu không gian. Doanh nghiệp có thể thêm những cột GEOMETRY vào trong bảng Redshift AWS và điền những truy vấn SQL trên các dữ liệu không gian và phi không gian. Tính năng này sẽ giúp doanh nghiệp lưu trữ, truy xuất cũng như xử lý các dữ liệu không gian, đồng thời, chúng ta sẽ liên tục cải thiện các thông tin kinh doanh mang tính chuyên sâu nhờ vào việc tích hợp các dữ liệu không gian vào những truy vấn phân tích của mình. Thông qua khả năng truy vấn một cách liền mạch hồ dữ liệu của AWS Redshift, doanh nghiệp có thể dễ dàng gia tăng, mở rộng hoạt động xử lý không gian ra ngoài hồ dữ liệu nhờ vào việc tích hợp các bảng bên ngoài trong các truy vấn không gian.
- Bản nháp của HyperLogLog
HyperLogLog chính là thuật toán mới, giúp doanh nghiệp ước tính mức độ hiệu quả cũng như số lượng gần đúng những giá trị riêng biệt bên trong một bộ dữ liệu. Bản nháp của HyperLogLog là một cấu trúc được đóng gói các thông tin về nhiều giá trị riêng biệt bên trong bộ dữ liệu. Doanh nghiệp có thể tận dụng bản nháp của HyperLogLog để đạt được rất nhiều lợi ích đáng kể về mặc hiệu năng cho những truy vấn tính toán các số liệu mang tính gần chính xác trên các bộ dữ liệu quy mô lớn, kèm theo đó là sai số tương đối trung bình nằm trong khoảng 0.01 – 0.6%.
Ngoài ra, AWS Redshift còn cung cấp cho doanh nghiệp kiểu dữ liệu hạng nhất HLLSKETCH cũng những hàm SQL có liên quan để xây dựng, duy trì và kết hợp nhiều bản nháp của HyperLogLog lại với nhau. Khả năng HyperLogLog của AWS Redshift sử dụng các kỹ thuật khắc phục vấn đề sai lệch và mang đến mức độ chính xác cao với việc chiếm dụng dung lượng bộ nhớ thấp.
- Các kiểu dữ liệu DATE và TIME
AWS Redshift cung cấp cho doanh nghiệp nhiều kiểu dữ liệu DATE – TIME – TIMETZ – TIMESTAMP – TIMESTAMPTZ giúp chúng ta có thể lưu trữ và xử lý các dữ liệu thời gian ngay tại gốc. Các kiểu dữ liệu TIME và TIMESTAMP có nhiệm vụ lưu trữ các dữ liệu thời gian không có thông tin về múi giờ, còn kiểu dữ liệu TIMETZ và TIMESTAMPTZ có vai trò lưu trữ các dữ liệu thời gian, bao gồm cả những thông tin về múi giờ. Doanh nghiệp có thể sử dụng những hàm SQL về ngày hoặc giờ khác nhau nhằm xử lý các giá trị về ngày và giờ bên trong các truy vấn của Redshift.
- Xử lý các dữ liệu với cấu trúc chưa hoàn chỉnh
Kiểu dữ liệu SUPER của AWS Redshift có nhiệm vụ lưu trữ các dữ liệu JSON cùng dữ liệu với cấu trúc chưa hoàn chỉnh khác bên trong những bảng Redshift AWS ngay tại gốc và triển khai ngôn ngữ truy vấn PartiQL nhằm xử lý một cách liền mạch các dữ liệu với cấu trúc chưa hoàn chỉnh này. Kiểu dữ liệu SUPER này không cần đến lược đồ và có thể cho phép doanh nghiệp lưu trữ nhiều giá trị kết hợp, lồng ghép với nhau, có thể chứa được các giá trị vô hướng Redshift, các dữ liệu theo mảng lồng ghép nhau cùng các cấu trúc lồng ghép nhau.
Ngôn ngữ truy vấn PartiQL cũng là một phần mở rộng của SQL, mang đến cho doanh nghiệp khả năng truy vấn vô cùng mạnh mẽ, chẳng hạn như: điều hướng các đối tượng và dữ liệu theo mảng, hủy bỏ việc lồng ghép các mảng, nhập dữ liệu động và các ngữ nghĩa mà không cần lược đồ. Công cụ này còn giúp doanh nghiệp triển khai các phân tích nâng cao, kết hợp các dữ liệu SQL với cấu trúc cổ điển cùng những dữ liệu SUPER với cấu trúc chưa hoàn chỉnh, đảm bảo hiệu năng vượt trội, có tính linh hoạt cao và dễ dàng sử dụng.
- Tích hợp với những công cụ của các bên thứ ba
AWS Redshift có rất nhiều tùy chọn hợp tác với các công cụ cũng như những chuyên gia hàng đầu trong lĩnh vực để nâng cao các khả năng tải, chuyển đổi và trực quan các hóa dữ liệu. Rất nhiều đối tác bên thứ ba đã xác nhận những giải pháp của họ tương thích với AWS Redshift, bao gồm: hoạt động tải và chuyển đổi các dữ liệu với những đối tác tích hợp dữ liệu, nâng cao quá trình phân tích các dữ liệu và chia sẻ nhiều thông tin chuyên sâu trên một quy mô rộng lớn với các đối tác nghiệp vụ thông minh, tiến hành xây dựng và triển khai các nền tảng phân tích khi hợp tác với những đối tác tư vấn – tích hợp hệ thống, triển khai các truy vấn – khám phá cũng như mô hình hóa các dữ liệu thông qua những công cụ và tiện ích của các đối tác cung cấp truy vấn và dịch vụ mô hình hóa dữ liệu.
TỐI ƯU HIÊU QUẢ Ở MỌI QUY MÔ
Tỷ lệ về hiệu năng theo mức chi phí của AWS Redshift tăng cao gấp 3 lần so với những kho dữ liệu về đám mây khác nhờ vào khả năng vô cùng tuyệt vời là tối ưu hóa một cách tự động nhằm cải thiện tốc độ của các truy vấn.
Những phiên bản RA3
Những phiên bản RA3 mang đến cho doanh nghiệp tỷ lệ hiệu năng theo mức chi phí cao gấp 3 lần so với bất cứ dịch vụ về kho dữ liệu đám mây nào khác. Những phiên bản AWS Redshift này sẽ tối đa hóa về mặt tốc độ dành cho khối lượng các công việc với yêu cầu về hiệu năng cao, đòi hỏi những năng lực lớn trong khía cạnh điện toán, sở hữu tính linh hoạt mạnh mẽ để triển khai các thanh toán riêng cho điện toán, đảm bảo độc lập với phân dung lượng lưu trữ thông qua việc chỉ định về số lượng các phiên bản mà doanh nghiệp cần.

–
Lưu trữ đạt hiệu quả và xử lý các truy vấn với mức hiệu năng cao
AWS Redshift mang đến hiệu năng truy vấn cực kỳ nhanh chóng trên những bộ dữ liệu với dung lượng nằm trong mức vài gigabyte đến mức hàng petabyte. Định dạng khi lưu trữ theo dạng cột, các phương thức nén dữ liệu cũng như bản đồ vùng hỗ trợ giảm lượng I/O sẽ rất cần thiết để thực hiện các truy vấn.
Bên cạnh những mã hóa đạt tiêu chuẩn ngành như Zstandard và LZO thì AWS Redshift cũng cung cấp cho doanh nghiệp mã hóa nén chuyên dụng là AZ64 dành cho những dạng số và ngày/giờ. Nhờ đó, chúng ta có thể tiết kiệm được dung lượng lưu trữ và mang đến mức hiệu năng truy vấn tối ưu.
Không giới hạn tính đồng thời
AWS Redshift cung cấp cho doanh nghiệp mức hiệu năng nhanh chóng và ổn định, dù là khi có hàng nghìn các truy vấn diễn ra đồng thời và dù cho người dùng truy vấn các dữ liệu bên trong kho dữ liệu AWS Redshift hay truy vấn các dữ liệu trực tiếp từ hồ dữ liệu Amazon S3 của chúng ta. Tính năng thay đổi quy mô một cách đồng thời bên trong AWS Redshift cũng hỗ trợ rất nhiều người dùng một cách đồng thời và các truy vấn mang tính đồng thời, hầu như không bị giới hạn về chất lượng của dịch vụ theo hướng nhất quán nhờ vào việc tăng thêm mức dung lượng tạm thời trong khoảng thời gian chỉ vài giây, ngay khi hoạt động đồng thời này tăng lên.
Chế độ xem được cụ thể hóa
Những chế độ xem được cụ thể hóa của AWS Redshift giúp doanh nghiệp đạt mức hiệu năng truy vấn nhanh hơn rất nhiều cho những khối lượng công việc về phân tích mang tính lặp lại hoặc có khả năng dự đoán, chẳng hạn như: tổng hợp các bảng thông tin, tiến hành truy vấn từ những công cụ BI, các tác vụ xử lý trích xuất, chuyển đổi và tải (hay ELT) dữ liệu. Doanh nghiệp có thể tận dụng những chế độ xem được cụ thể hóa này để có thể dễ dàng triển khai các hoạt động lưu trữ và quản lý những kết quả đã được tính toán sẵn bởi một câu lệnh SELECT với tham chiếu hướng đến một hoặc đến nhiều bảng, cả những bảng nằm bên ngoài. Những truy vấn tiếp theo sau tham chiếu hướng đến chế độ xem được cụ thể hóa có khả năng triển khai nhanh chóng hơn rất nhiều nhờ doanh nghiệp tái sử dụng các kết quả đã được tính toán sẵn này. AWS Redshift có thể tiến hành duy trì hiệu quả ngày càng cao các chế độ xem được cụ thể hóa để có thể tiếp tục đem đến nhiều lợi ích về hiệu năng với độ trễ thấp.
Chế độ xem được cụ thể hóa một cách tự động
Đối với các ứng dụng, bảng điều khiển, những báo cáo và các truy vấn có khả năng tùy biến phụ thuộc vào các dữ liệu đều cần được chỉnh sửa và tối ưu hóa với những yêu cầu cụ thể về thời gian, chi phí cũng như các tài nguyên. Chế độ xem được cụ thể hóa như đã đề cập ở các phần nội dung trước chính là công cụ cực kỳ mạnh mẽ, giúp doanh nghiệp có thể cải thiện về mặt hiệu năng truy vấn, đồng thời, chúng ta sẽ thiết lập được công cụ này khi có khối lượng các công việc.
Tuy nhiên, vẫn có nhiều trường hợp doanh nghiệp đã nâng cao và thay đổi về khối lượng các công việc với những mẫu truy vấn không có khả năng được dự đoán trước. Lúc này, chế độ xem được cụ thể hóa một cách tự động sẽ cải thiện cho chúng ta về mặt thông lượng truy vấn, tối thiểu hóa độ trễ truy vấn và rút ngắn các khoảng thời gian thực thi thông qua tính năng tự động làm mới, tự động thiết lập lại các truy vấn, làm mới theo hướng tăng dần và liên tục giám sát các cụm AWS Redshift. Redshift AWS sẽ cân bằng việc xây dựng và quản lý những chế độ xem được cụ thể hóa một cách tự động với khả năng triển khai các tài nguyên theo mức tối thiểu.
Ứng dụng máy học nhằm tối đa hóa yếu tố hiệu năng và thông lượng
Những tính năng máy học ML nâng cao bên trong AWS Redshift cung cấp cho doanh nghiệp mức hiệu năng và thông lượng cao, ngay cả đối với khối lượng các công việc khác nhau hoặc những hoạt động diễn ra đồng thời của các đối tượng người dùng khác nhau. AWS Redshift ứng dụng những thuật toán cực kỳ tinh vi nhằm dự đoán và phân loại nhiều truy vấn đến và chúng sẽ được dựa trên các khoảng thời gian vận hành cũng như các yêu cầu về tài nguyên của những truy vấn đó. Từ đó, doanh nghiệp có thể quản lý một cách linh hoạt hiệu năng, tính đồng thời và ưu tiên các khối lượng công việc mang tính quan trọng trong doanh nghiệp.
Tính năng tăng tốc các truy vấn ngắn (hay SQA) có nhiệm vụ gửi những truy vấn ngắn từ vị trí các ứng dụng, chẳng hạn như bảng thông tin đến vị trí hàng đợi một cách nhanh chóng để việc xử lý này được diễn ra ngay lập tức thay vì phải bị bỏ lại phía sau những truy vấn lớn. Tính năng quản lý các khối lượng công việc một cách tự động (hay WLM) sẽ ứng dụng công nghệ ML giúp cho việc quản lý bộ nhớ trở nên linh hoạt và đạt được tính đồng thời, từ đó tối đa hóa thông lượng của các truy vấn.
Ngoài ra, doanh nghiệp cũng dễ dàng ưu tiên mức độ của các truy vấn có tính quan trọng nhất, ngay cả khi có đến hàng trăm nghìn các truy vấn đang được gửi đi. AWS Redshift cũng chính là một hệ thống có khả năng tự học, luôn quan sát các khối lượng công việc của những đối tượng người dùng khác nhau, xác định được những cơ hội cải thiện về mặt hiệu năng của hệ thống khi mức sử dụng ngày càng tăng lên. Từ đó, chúng ta có thể ứng dụng linh hoạt, xuyên suốt các giải pháp tối ưu hóa, đưa ra những khuyến nghị thông qua chức năng Redshift Advisor khi hệ thống cần một hành động chính xác, rõ ràng của người dùng nhằm gia tăng hiệu năng Redshift mạnh mẽ hơn nữa.
Lưu trữ các kết quả vào bộ nhớ đệm
AWS Redshift ứng dụng tính năng lưu trữ các kết quả vào bộ nhớ đệm nhằm tạo ra các phản hồi trong trong chưa đầy một giây dành cho những truy vấn lặp lại. Các bảng thông tin, những hình ảnh mang tính trực quan hóa cùng các công cụ nghiệp vụ thông minh triển khai các truy vấn lặp lại đều sẽ gia tăng đáng kể về mặt hiệu năng. Mỗi khi xuất hiện truy vấn, AWS Redshift sẽ tìm kiếm bên trong bộ nhớ đệm các kết quả đã được lưu trữ lại từ lần triển khai trước. Nếu tìm ra các kết quả đã được lưu trữ bên trong bộ nhớ đệm cũng như các dữ liệu chưa thay đổi, những kết quả được lưu trữ bên trong bộ nhớ đệm sẽ ngay lập tức được hệ thống trả về cho chúng ta thay vì phải thiết lập lại các truy vấn.
Lưu trữ kho dữ liệu với quy mô đến mức petabyte
Chỉ thông qua một vài thao tác nhấp chuột đơn giản trong bảng điều khiển hệ thống hoặc với một lệnh gọi kết nối API, doanh nghiệp có thể thay đổi dễ dàng số lượng hoặc các loại nút mạng bên trong kho dữ liệu cũng như tiến hành tăng – giảm về mặt quy mô của các dữ liệu mỗi khi nhu cầu thay đổi. Với đặc điểm dung lượng lưu trữ được kiểm soát và quản lý chặt chẽ, dung lượng được tự động thêm vào để hỗ trợ cho khối lượng các công việc có thể lên đến 8 PB dữ liệu nén.
Ngoài ra, doanh nghiệp cũng có thể thiết lập và triển khai các truy vấn đối với hàng petabyte dữ liệu bên trong Amazon S3 mà không cần phải tải hoặc thực hiện việc chuyển đổi bất cứ dữ liệu nào nhờ có tính năng AWS Redshift Spectrum. Ngoài ra, chúng ta có thể ứng dụng Amazon S3 như một hồ dữ liệu với tính sẵn sàng cao, đảm bảo an toàn và tiết kiệm chi phí cho việc lưu trữ các dữ liệu không giới hạn theo đúng những định dạng dữ liệu mở. AWS Redshift Spectrum cũng triển khai các truy vấn trên hàng nghìn nút mạng theo dạng song song để mang đến kết quả nhanh chóng, dù là ở mức độ phức tạp của các truy vấn hoặc lượng dữ liệu như thế nào.
Những tùy chọn tính toán linh hoạt mức chi phí
AWS Redshift là kho dữ liệu có khả năng tiết kiệm chi phí nhất hiện nay và doanh nghiệp có thể tối ưu hóa phương thức thanh toán cho mình. Chúng ta có thể bắt đầu với các khoản chi phí nhỏ chỉ từ $0.25/giờ mà không cần phải cam kết bất cứ vấn đề gì và tăng mức chi phí lên chỉ với $1,000/terabyte/năm. AWS Redshift cũng chính là kho dữ liệu đám mây duy nhất hiện nay cung cấp cho doanh nghiệp phương thức tính mức chi phí tùy thuộc vào nhu cầu mà không cần bất cứ khoản phí trả trước nào.
Mức giá của phiên bản đặt trước có thể sẽ giúp chúng ta tiết kiệm đến 75% nhờ vào việc cam kết theo kỳ hạn 1 – 3 năm, đồng thời, mức giá theo từng truy vấn cũng sẽ được dựa vào số lượng các dữ liệu được quét bên trong hồ dữ liệu Amazon S3 của mình. Mức chi phí của AWS Redshift sẽ bao gồm: nén các dữ liệu, bảo mật tích hợp, lưu trữ dự phòng và việc truyền dữ liệu. Khi dung lượng các dữ liệu tăng lên, doanh nghiệp có thể sử dụng bộ nhớ được quản lý bên trong những phiên bản RA3 để giúp lưu trữ các dữ liệu đảm bảo tiết kiệm với mức chi phí chỉ $0.024/GB/tháng.
Các loại nút với giá trị tốt nhất đối với khối lượng các công việc
Doanh nghiệp có thể lựa chọn 1 trong 3 loại phiên bản sau nhằm để tối ưu hóa AWS Redshift đối với nhu cầu về lưu trữ kho dữ liệu của mình, bao gồm: nút RA3, nút điện toán với mật độ cao và nút lưu trữ với mật độ cao. Đối với việc thay đổi về quy mô của các cụm hoặc hoạt động chuyển đổi giữa những loại nút với nhau, doanh nghiệp chỉ cần thực hiện một lệnh gọi kết nối API hoặc thực hiện một số nhấp chuột trên bảng điều khiển hệ thống quản lý Amazon Web Services.
- Những nút RA3 hỗ trợ doanh nghiệp thay đổi về quy mô lưu trữ một cách độc lập với điện toán. Nhờ có các nút RA3 này, chúng ta sẽ có được kho dữ liệu với mức hiệu năng cao, giúp lưu trữ các dữ liệu hiệu quả bên trong một lớp lưu trữ mang tính riêng biệt. Doanh nghiệp chỉ cần tiến hành thay đổi về mặt kích thước của kho dữ liệu sao cho phù hợp nhất với mức hiệu năng truy vấn mà chúng ta cần.
- Các nút điện toán với mật độ cao (hay DC) cho phép doanh nghiệp thiết lập nên kho dữ liệu sở hữu mức hiệu năng rất cao thông qua các CPU có tốc độ cao, RAM với dung lượng lớn cùng ổ đĩa thể rắn SSD. Đây chính là sự lựa chọn tuyệt vời nhất dành cho các dữ liệu ít hơn 500GB.
- Những nút lưu trữ với mật độ cao (hay DS2) hỗ trợ doanh nghiệp bạn thiết lập nên một kho dữ liệu lớn nhờ vào ổ đĩa cứng HDD với mức chi phí thấp khi chúng ta mua những phiên bản đặt trước với khoản thời gian sử dụng là 3 năm. Phần lớn các khách hàng triển khai trên các cụm DS2 có khả năng di chuyển khối lượng các công việc sang các cụm RA3 và đạt được mức hiệu năng lớn gấp 2 lần cũng như nhiều dung lượng lưu trữ hơn so với loại cùng chi phí là DS2.
BẢO MẬT AN TOÀN VÀ TUÂN THỦ CÁC CAM KẾT
Cuối cùng, AWS Redshift đảm bảo an toàn bảo mật và tuân thủ các cam kết. Đây chính là một lợi ích và tính năng hết sức tuyệt vời của dịch vụ này.

–
Mã hóa hoàn chỉnh
Chỉ với một số thao tác thiết lập về các thông số, doanh nghiệp có thể cài đặt AWS Redshift sử dụng SSL để thiết lập vấn đề bảo mật các dữ liệu khi truyền và mã hóa AES-256 được tăng tốc nhờ vào phần cứng đối với các dữ liệu đang được lưu trữ. Nếu chúng ta lựa chọn kích hoạt khả năng mã hóa các dữ liệu đang được lưu trữ, toàn bộ các dữ liệu được ghi vào các ổ đĩa cũng như tất cả các bản sao lưu đều sẽ được hệ thống tiến hành mã hóa. Lúc này, AWS Redshift sẽ quản lý khóa theo dạng mặc định.
Cách ly kết nối mạng
AWS Redshift giúp doanh nghiệp cấu hình các quy tắc tường lửa nhằm kiểm soát các truy cập thông qua các kết nối mạng đến cụm kho các dữ liệu của mình. Chúng ta cũng có thể triển khai AWS Redshift bên trong Amazon Virtual Private Cloud (hay VPC) nhằm cách ly cụm kho các dữ liệu bên trong mạng ảo của riêng mình và kết nối đến các cơ sở hạ tầng công nghệ thông tin hiện có thông qua VPN IPsec đã được tiến hành mã hóa theo các tiêu chuẩn của ngành.
Kiểm tra và tuân thủ
AWS Redshift được tích hợp với giải pháp AWS CloudTrail giúp doanh nghiệp có thể kiểm tra toàn bộ các lệnh gọi kết nối API Redshift. AWS Redshift cũng có nhiệm vụ ghi lại nhật ký tất cả các thao tác SQL, chẳng hạn như những lượt kết nối, các truy vấn cũng như những thay đổi bên trong của kho dữ liệu. Chúng ta có thể truy cập vào những nhật ký này nhờ vào việc triển khai các truy vấn SQL trong bảng hệ thống hoặc tiến hành lưu trữ các nhật ký vào một vị trí an toàn bên trong Amazon S3. AWS Redshift cũng đảm bảo tuân thủ những yêu cầu về SOC1, SOC2, SOC3 và PCI DSS cấp 1.
Token hóa
Những hàm dành do người dùng được xác định (hay UDF) của AWS Lambda giúp doanh nghiệp có thể triển khai các hàm Lambda đối với UDF bên trong AWS Redshift và gọi các hàm từ những truy vấn Redshift SQL. Nhờ có tính năng này, doanh nghiệp có thể xây dựng nên các phần mở rộng có khả năng tùy chỉnh đối với các truy vấn SQL của mình và đạt được sự tích hợp một cách chặt chẽ hơn đối với nhiều dịch vụ khác hoặc đối với những sản phẩm của các bên thứ ba.
Doanh nghiệp có thể thiết lập UDF Lambda nhằm kích hoạt token hóa từ phía bên ngoài, bảo vệ các dữ liệu, tiến hành nhận dạng hoặc loại bỏ các khả năng về nhận dạng dữ liệu thông qua việc tích hợp với những nhà cung cấp như Protegrity. Ngoài ra, chúng ta cũng có thể bảo vệ hoặc ngừng bảo vệ các dữ liệu có tính nhạy cảm dựa vào các quyền và nhóm người dùng ngay trong thời gian truy vấn.
Kiểm soát chi tiết các truy cập
Kiểm soát các bảo mật theo cột và hàng một cách chi tiết sẽ đảm bảo các đối tượng người dùng chỉ thấy được các dữ liệu mà họ được cấp quyền truy cập. AWS Redshift cũng được tích hợp với AWS Lake Formation, đảm bảo những biện pháp để kiểm soát các truy cập vào của Lake Formation sẽ được triển khai cho những truy vấn Redshift AWS trên các dữ liệu bên trong hồ dữ liệu.
KẾT LUẬN
AWS Redshift chính là một dịch vụ hỗ trợ các doanh nghiệp trong quá trình lưu trữ các dữ liệu theo quy mô hàng petabyte cực kỳ nhanh chóng và mạnh mẽ. Triển khai hiệu quả AWS Redshift nói chung và các dịch vụ Amazon Web Services, doanh nghiệp sẽ đạt được những kết quả hết sức tuyệt vời trong quá trình chuyển đổi số.
Vina Aspire là công ty tư vấn, cung cấp các giải pháp, dịch vụ CNTT, An ninh mạng, bảo mật & an toàn thông tin tại Việt Nam. Đội ngũ của Vina Aspire gồm những chuyên gia, cộng tác viên giỏi, có trình độ, kinh nghiệm và uy tín cùng các nhà đầu tư, đối tác lớn trong và ngoài nước chung tay xây dựng.
Các Doanh nghiệp, tổ chức có nhu cầu liên hệ Công ty Vina Aspire theo thông tin sau:
Email: info@vina-aspire.com | Website: www.vina-aspire.com
Tel: +84 9024 17606 | Fax: +84 28 3535 0668
![]()
Vina Aspire – Vững bảo mật, trọn niềm tin