10 thuật toán trong Machine Learning
1. Linear Regression (Hồi quy tuyến tính)
Hồi quy tuyến tính là một trong những thuật toán nổi tiếng nhất trong Machine Learning. Đây là một phương pháp thống kê để hồi quy dữ liệu với biến phụ thuộc có giá trị liên tục trong khi các biến độc lập có thể có một trong hai giá trị liên tục hoặc là giá trị phân loại.
Để hiểu chức năng hoạt động của thuật toán này, hãy tưởng tượng bạn sẽ sắp xếp các khúc gỗ ngẫu nhiên theo thứ tự tăng dần về trọng lượng của chúng. Tuy nhiên, bạn không thể cân từng khúc gỗ. Bạn phải đoán trọng lượng của nó chỉ bằng cách nhìn vào chiều cao và chu vi của khúc gỗ (phân tích trực quan) và sắp xếp chúng bằng cách sử dụng kết hợp các thông số có thể nhìn thấy này. Đây là hồi quy tuyến tính trong Machine Learning.
Hồi quy tuyến tính được phát minh vào khoảng hơn 200 năm trước và được nghiên cứu rộng rãi. Đây là một thuật toán tốt, nhanh chóng và dễ sử dụng.
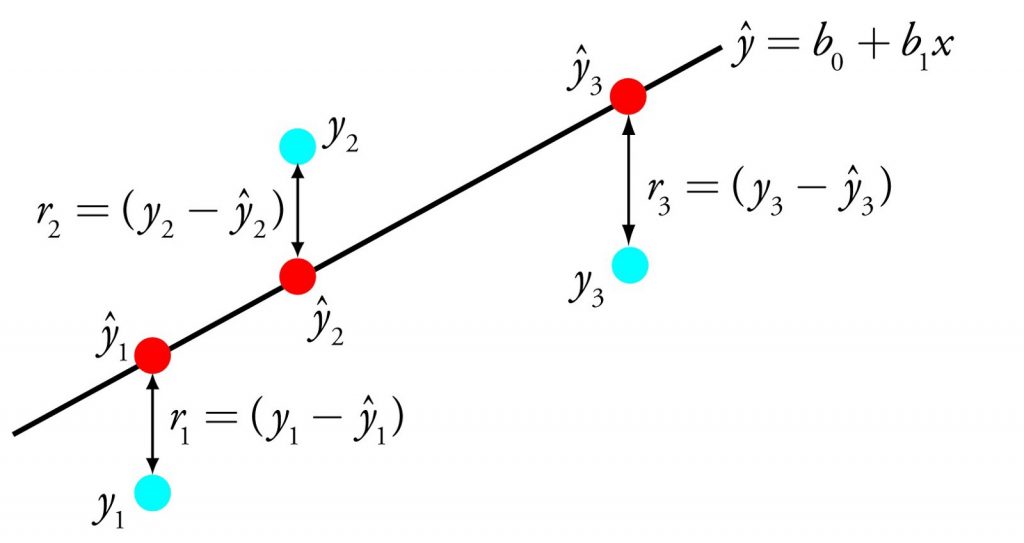
Thuật toán hồi quy tuyến tính
2. Logistic Regression (Hồi quy logistic)
Logistic Regression (hay còn được gọi là hồi quy logitic) được sử dụng để ước tính các giá trị rời rạc (thường là các giá trị nhị phân như 0/1) từ một tập hợp các biến độc lập. Hồi quy logistic giúp dự đoán xác suất của một sự kiện bằng cách khớp dữ liệu với một hàm logit.
Tương tự hồi quy tuyến tính, hồi quy logistic sẽ hoạt động tốt hơn khi loại bỏ các thuộc tính không liên quan đến biến đầu ra hoặc các thuộc tính tương tự nhau. Đây là mô hình có thể học được nhanh và có hiệu quả với các vấn đề phân loại nhị phân.
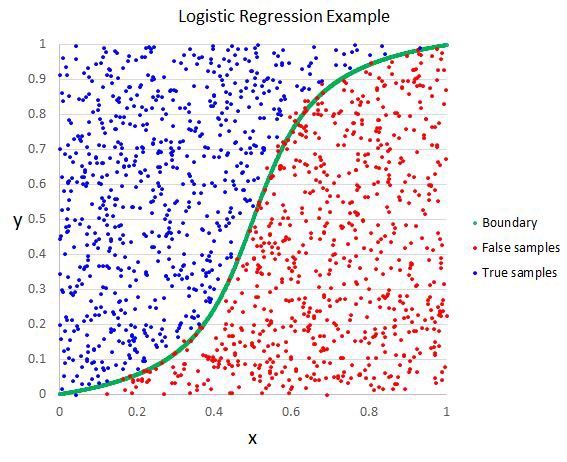
Thuật toán hồi quy logistic
3. Decision Tree (Cây quyết định)
Thuật toán Decision Tree trong Machine Learning là một trong những thuật toán phổ biến nhất được sử dụng hiện nay. Đây là một thuật toán học tập có giám sát được sử dụng để phân loại các vấn đề. Decisiom Tree hoạt động tốt khi phân loại cho cả biến phụ thuộc phân loại và biến phụ thuộc liên tục. Trong thuật toán này có thể chia tổng thể thành hai hoặc nhiều tập đồng nhất dựa trên các thuộc tính hoặc biến độc lập quan trọng nhất.
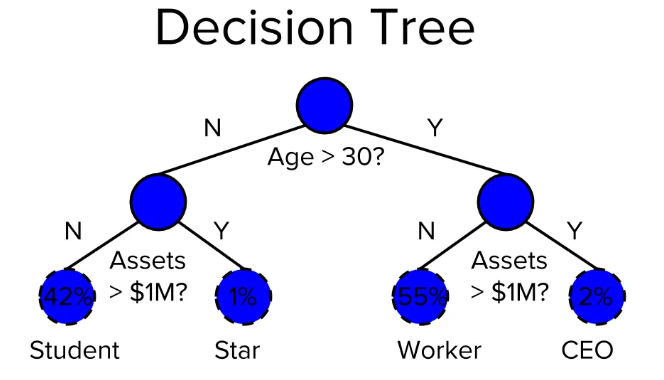
Thuật toán Decision Tree
4. Thuật toán Support Vector Machine (Thuật toán SVM)
Thuật toán SVM là một phương pháp thuật toán phân loại, trong đó bạn vẽ biểu đồ dữ liệu thô dưới dạng các điểm trong không gian N chiều (với n là số đối tượng bạn có). Sau đó, giá trị của mỗi đối tượng địa lý được gắn với một tọa độ cụ thể, giúp dễ dàng phân loại dữ liệu. Các dòng đó được gọi là bộ phân loại có thể được sử dụng để tách dữ liệu và vẽ chúng trên biểu đồ.
Thuật toán SVM giải quyết được nhiều vấn đề lớn như phân loại hình ảnh có phạm vị rộng, hiển thị quảng cáo, phát hiện giới tính bằng hình ảnh.
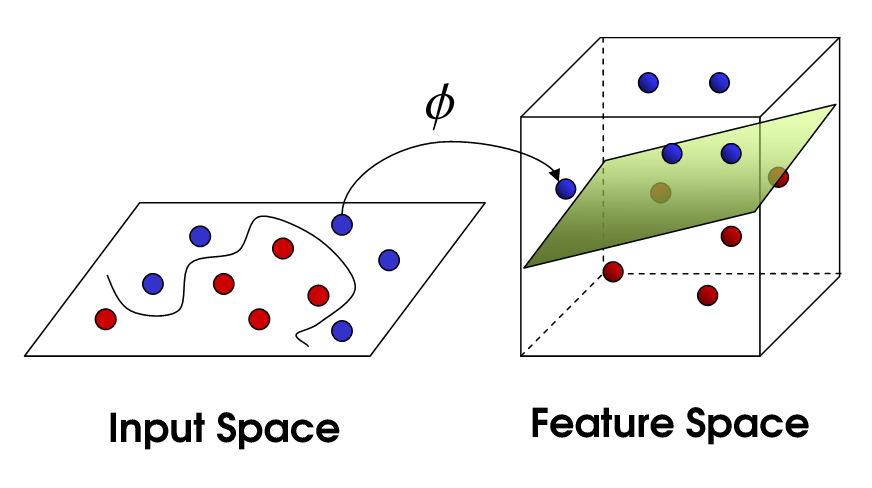
Thuật toán SVM
Naive Bayes là một thuật toán đơn giản nhưng có mô hình tiên đoán vô cùng chính xác. Mô hình Naive Bayes giả định rằng sự hiện diện của một đối tượng cụ thể trong một lớp không liên quan đến sự hiện diện của bất kỳ đối tượng địa lý nào khác.
Ngay cả khi các tính năng này có liên quan với nhau, bộ phân loại Naive Bayes sẽ xem xét tất cả các thuộc tính này một cách độc lập khi tính toán xác suất và đưa ra một kết quả cụ thể. Mô hình Naive Bayes rất dễ xây dựng và hữu ích cho các bộ dữ liệu lớn với các vấn đề phức tạp.

Thuật toán Naive Bayes
6. Thuật toán K-Nearest Neighbors (KNN)
Thuật toán này có thể được áp dụng cho cả bài toán phân loại và bài toán hồi quy. Rõ ràng, trong ngành Khoa học Dữ liệu, KNN được sử dụng rộng rãi hơn để giải quyết các vấn đề phân loại. Đây là một thuật toán đơn giản lưu trữ tất cả các trường hợp có sẵn và phân loại bất kỳ trường hợp mới nào bằng cách lấy đa số phiếu bầu của K neighbor. Sau đó, trường hợp được gán cho lớp mà nó có điểm chung nhất. Một chức năng khoảng cách thực hiện phép đo này.
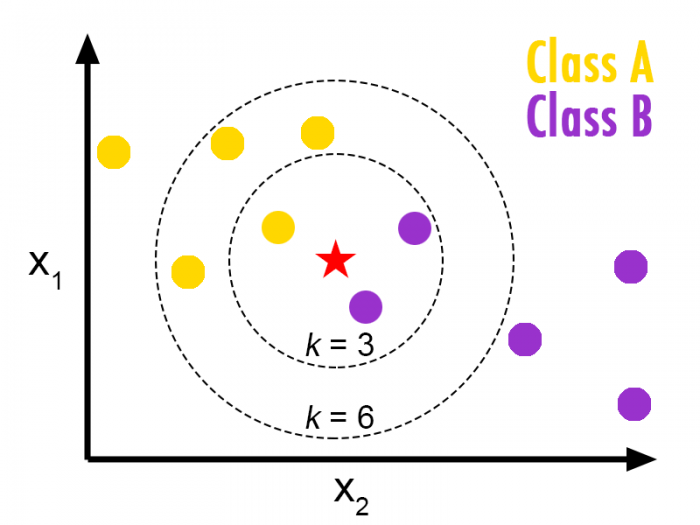
Thuật toán KNN
KNN có thể được hiểu một cách dễ dàng bằng cách so sánh nó với cuộc sống thực. Ví dụ: Nếu bạn muốn biết thông tin về một người, hãy nói chuyện với bạn bè và đồng nghiệp của họ.
Tuy nhiên, cần cân nhắc vài điều trước khi chọn KNN như: Các biến phải được chuẩn hóa, nếu không các biến có phạm vi cao hơn có thể làm sai lệch thuật toán; dữ liệu vẫn cần được xử lý trước.
K-Means là một thuật toán học tập không giám sát để giải quyết các vấn đề phân cụm. Các tập dữ liệu được phân loại thành một số cụm cụ thể (hãy gọi số đó là K) theo cách mà tất cả các điểm dữ liệu trong một cụm là đồng nhất và không đồng nhất với dữ liệu trong các cụm khác.
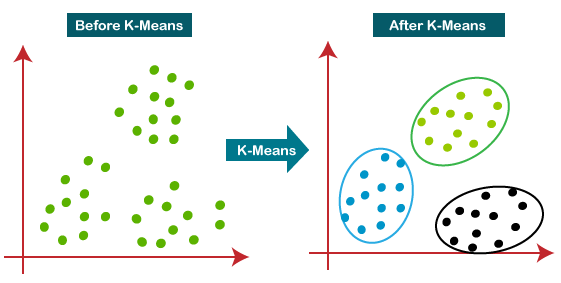
Cách K-mean tạo thành các cụm:
- Thuật toán K-mean chọn K số điểm cho mỗi cụm, gọi là centroid.
- Mỗi điểm dữ liệu tạo thành một cụm với các trung tâm gần nhất, tức là cụm K.
- Tạo ra các trung tâm mới dựa trên các cụm thành viên hiện có.
- Với những trung tâm mới này, khoảng cách gần nhất cho mỗi điểm dữ liệu được xác định. Quá trình này được lặp lại cho đến khi các trung tâm không thay đổi
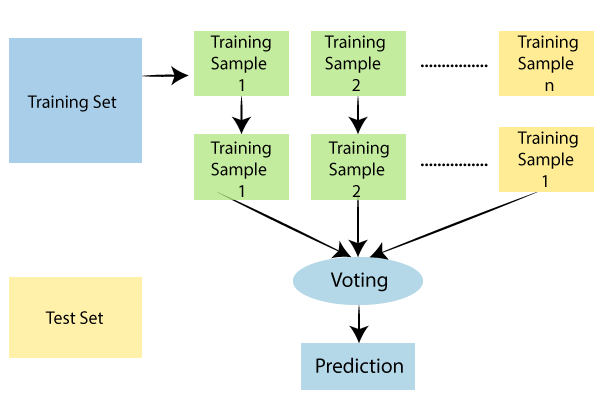
Một tập hợp các Decision Tree được gọi là Random Forest. Để phân loại một đối tượng mới dựa trên các thuộc tính của nó, mỗi cây sẽ được phân loại, và “vote” cho lớp đó.
Thuật toán Random Forest hoạt động theo các bước sau:
- Chọn các mẫu ngẫu nhiên từ tập tài liệu đã cho.
- Thiết lập Decision Tree cho từng mẫu và nhận kết quả dự đoán mỗi Decision Tree.
- Bỏ phiếu cho mỗi kết quả dự đoán.
- Chọn kết quả được bỏ phiếu nhiều nhất làm kết quả.
9. Thuật toán Dimensionality Reduction (Thuật toán giảm kích thước)
Trong thế giới ngày nay, một lượng lớn dữ liệu đang được các công ty, cơ quan chính phủ và tổ chức nghiên cứu lưu trữ và phân tích. Các dữ liệu thô này chứa rất nhiều thông tin, thách thức ở đây là phải xác định được các mẫu và biến quan trọng.
Nói một cách đơn giản, Dimensionality Reduction là việc chuyển đổi dữ liệu từ không gian chiều cao thành không gian chiều thấp để biểu diễn chiều thấp giữ lại một số thuộc tính có ý nghĩa của dữ liệu ban đầu.
Các thuật toán giảm kích thước, hay giảm thứ nguyên như Decision Tree, Factor Analysis, Missing Value Ratio và Random Forest có thể giúp bạn tìm thấy các chi tiết có liên quan.
10. Thuật toán Gradient Boosting và thuật toán AdaBoosting
Đây là các thuật toán thúc đẩy được sử dụng khi phải xử lý một lượng lớn dữ liệu để đưa ra dự đoán với độ chính xác cao. Boosting (tăng cường) là một thuật toán học tập tổng hợp kết hợp sức mạnh dự đoán của một số công cụ ước tính cơ sở để cải thiện độ mạnh mẽ.
AdaBoost là một thuật toán học mạnh, giúp đẩy nhanh việc tạo ra một bộ phân loại mạnh. Đây là thuật toán boosting thành công đầu tiên được phát triển để phân loại nhị phân.
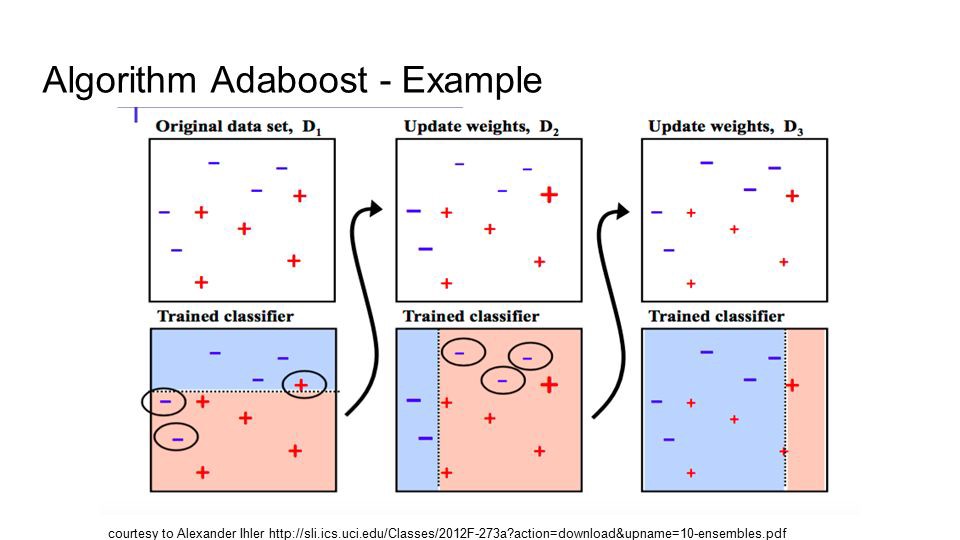
Thuật toán Boosting và Adaboosting
Những câu hỏi thường gặp về Machine Learning
1. Ví dụ về Machine Learning là gì?
Nhận dạng hình ảnh là một ví dụ phổ biến về Machine Learning mà bạn có thể tìm hiểu.
Nó có thể xác định một đối tượng dưới dạng ảnh kỹ thuật số, dựa trên cường độ của các pixel trong ảnh đen trắng hoặc ảnh màu.
2. Sự khác biệt giữa AI và Machine Learning là gì?
Trí tuệ nhân tạo là công nghệ cho phép máy mô phỏng hành vi của con người. Machine Learning là một tập hợp con của AI cho phép máy tự động học từ dữ liệu trong quá khứ mà không cần lập trình một cách rõ ràng .
Mục tiêu của AI là tạo ra một hệ thống máy tính thông minh giống như con người để giải quyết các vấn đề phức tạp.
3. Machine Learning có khó không?
Mặc dù nhiều công cụ Machine Learning nâng cao khó sử dụng và đòi hỏi nhiều kiến thức phức tạp về toán học, thống kê và kỹ thuật phần mềm nâng cao, nhưng người mới bắt đầu có thể bắt đầu học với những kiến thức cơ bản và sau đó có thể tiếp cận rộng rãi.
Vina Aspire là công ty tư vấn, cung cấp các giải pháp, dịch vụ CNTT, An ninh mạng, bảo mật & an toàn thông tin tại Việt Nam. Đội ngũ của Vina Aspire gồm những chuyên gia, cộng tác viên giỏi, có trình độ, kinh nghiệm và uy tín cùng các nhà đầu tư, đối tác lớn trong và ngoài nước chung tay xây dựng.
Các Doanh nghiệp, tổ chức có nhu cầu liên hệ Công ty Vina Aspire theo thông tin sau:
Email: info@vina-aspire.com | Website: www.vina-aspire.com
Tel: +84 944 004 666 | Fax: +84 28 3535 0668
![]()
Vina Aspire – Vững bảo mật, trọn niềm tin