Máy học trong an ninh mạng
Tập hợp cây quyết định, băm nhạy địa phương, mô hình hành vi hoặc phân cụm luồng đến – tất cả các phương pháp học máy (ML) được thiết kế để đáp ứng các yêu cầu bảo mật trong thế giới thực: tỷ lệ dương tính sai thấp, khả năng diễn giải và khả năng chống lại kẻ thù tiềm ẩn.
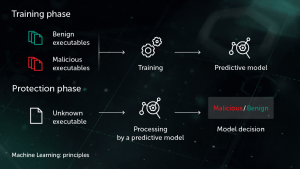
Arthur Samuel, nhà tiên phong trong lĩnh vực trí tuệ nhân tạo, đã mô tả học máy là một tập hợp các phương pháp và công nghệ “cung cấp cho máy tính khả năng học hỏi mà không cần được lập trình rõ ràng”. Trong một trường hợp cụ thể về học có giám sát để chống phần mềm độc hại, nhiệm vụ có thể được xây dựng như sau: đưa ra một tập hợp các tính năng đối tượng X và nhãn đối tượng tương ứng Y làm đầu vào, tạo một mô hình sẽ tạo ra các nhãn chính xác Y ‘cho các nhãn chưa từng thấy trước đó đối tượng thử nghiệm X ‘. X có thể là một số tính năng đại diện cho nội dung hoặc hành vi của tệp (thống kê tệp, danh sách các hàm API đã sử dụng, v.v.) và nhãn Y có thể chỉ đơn giản là “phần mềm độc hại” hoặc “lành tính” (trong những trường hợp phức tạp hơn, chúng tôi có thể quan tâm đến một khoản tiền phạt- phân loại cụ thể như Virus, Trojan-Downloader, Adware, v.v.). Trong trường hợp học tập không có giám sát, quan tâm nhiều hơn đến việc tiết lộ cấu trúc ẩn của dữ liệu – ví dụ: tìm các nhóm đối tượng tương tự hoặc các đặc điểm có tương quan cao.
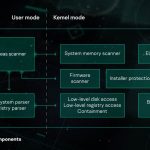
Tính năng bảo vệ đa lớp, thế hệ tiếp theo của Kaspersky Lab sử dụng rộng rãi các phương pháp học máy trên tất cả các giai đoạn của quá trình phát hiện – từ các phương pháp phân nhóm có thể mở rộng được sử dụng để xử lý trước luồng tệp đến trong cơ sở hạ tầng cho đến các mô hình mạng thần kinh sâu mạnh mẽ và nhỏ gọn để phát hiện hành vi sẽ hoạt động trực tiếp trên máy móc người dùng. Những công nghệ này được thiết kế theo cách để giải quyết một số yêu cầu quan trọng đối với mô hình học máy trong các ứng dụng bảo mật thông tin trong thế giới thực, tức là tỷ lệ tích cực giả cực thấp, khả năng diễn giải của mô hình và độ chắc chắn đối với kẻ thù tiềm năng.
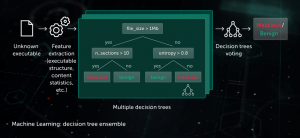
Tập hợp cây quyết định
Trong cách tiếp cận này, mô hình dự đoán có dạng một tập hợp các cây quyết định (ví dụ: rừng ngẫu nhiên hoặc cây tăng độ dốc). Mỗi nút không phải lá của cây chứa một số câu hỏi liên quan đến các tính năng của tệp, trong khi các nút lá chứa quyết định cuối cùng của cây đối với đối tượng. Trong giai đoạn thử nghiệm, mô hình đi qua cây bằng cách trả lời các câu hỏi trong các nút với các tính năng tương ứng của đối tượng đang được xem xét. Ở giai đoạn cuối cùng, các quyết định của nhiều cây được tính trung bình theo cách cụ thể của thuật toán để đưa ra quyết định cuối cùng về đối tượng.
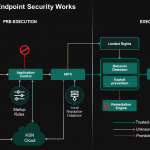
Mô hình này có lợi cho giai đoạn bảo vệ Chủ động trước khi thực thi trên trang web điểm cuối. Một trong những ứng dụng của chúng tôi về công nghệ này là Cloud ML dành cho Android được sử dụng để phát hiện các mối đe dọa trên thiết bị di động.

Hàm băm tương tự (Hàm băm nhạy cảm với địa phương)
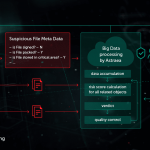
Các mã băm được sử dụng để tạo “dấu chân” của phần mềm độc hại trong thời xưa rất nhạy cảm với mọi thay đổi nhỏ trong tệp. Hạn chế này đã được khai thác bởi những người viết phần mềm độc hại thông qua các kỹ thuật làm xáo trộn như đa hình phía máy chủ: những thay đổi nhỏ trong phần mềm độc hại đã loại bỏ nó. Hàm băm tương tự (hoặc hàm băm nhạy cảm với địa phương) là một phương pháp để phát hiện các tệp độc hại tương tự. Để thực hiện việc này, hệ thống trích xuất các tính năng của tệp và sử dụng phương pháp học phép chiếu trực giao để chọn các tính năng quan trọng nhất. Sau đó, nén dựa trên ML được áp dụng để các vectơ giá trị của các tính năng tương tự được chuyển đổi thành các mẫu tương tự hoặc giống hệt nhau. Phương pháp này cung cấp khả năng tổng quát hóa tốt và giảm đáng kể kích thước của cơ sở bản ghi phát hiện, vì một bản ghi hiện có thể phát hiện toàn bộ họ phần mềm độc hại đa hình.
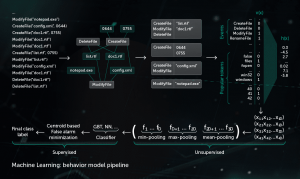
Mô hình hành vi
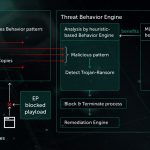
Thành phần giám sát cung cấp nhật ký hành vi – chuỗi các sự kiện hệ thống xảy ra trong quá trình thực hiện cùng với các đối số tương ứng. Để phát hiện hoạt động độc hại trong dữ liệu nhật ký được quan sát, mô hình của chúng tôi nén chuỗi sự kiện thu được thành một tập hợp các vectơ nhị phân và huấn luyện mạng nơ-ron sâu để phân biệt nhật ký sạch và độc hại.
Việc phân loại đối tượng theo mô hình Hành vi được sử dụng bởi cả mô-đun phát hiện tĩnh và động trong các sản phẩm của Kaspersky ở phía điểm cuối.
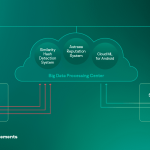
Học máy đóng một vai trò quan trọng không kém khi xây dựng cơ sở hạ tầng xử lý phần mềm độc hại trong phòng thí nghiệm thích hợp. Kaspersky Lab sử dụng nó cho các mục đích cơ sở hạ tầng sau:
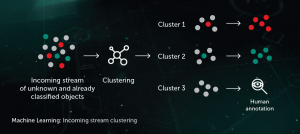
Nhóm luồng đến
Các thuật toán phân cụm dựa trên ML cho phép chúng tôi tách một cách hiệu quả khối lượng lớn các tệp không xác định đến cơ sở hạ tầng của chúng tôi thành một số lượng hợp lý các cụm, một số trong số đó có thể được xử lý tự động dựa trên sự hiện diện của một đối tượng đã được chú thích bên trong nó.
Các mô hình phân loại quy mô lớn
Một số mô hình phân loại mạnh mẽ nhất (như một khu rừng quyết định ngẫu nhiên khổng lồ) yêu cầu lượng lớn tài nguyên (thời gian xử lý, bộ nhớ) cùng với các trình trích xuất tính năng đắt tiền (ví dụ: có thể cần xử lý qua hộp cát để ghi nhật ký hành vi chi tiết). Do đó, sẽ hiệu quả hơn nếu giữ và chạy các mô hình trong phòng thí nghiệm, sau đó chắt lọc kiến thức thu được từ các mô hình đó thông qua đào tạo một số mô hình phân loại nhẹ về các quyết định đầu ra của mô hình lớn hơn.
Bảo mật của Học máy
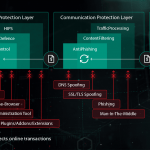
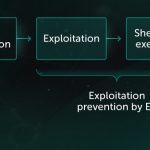
Các thuật toán ML, một khi được giải phóng khỏi giới hạn của phòng thí nghiệm và được đưa vào thế giới thực, có thể dễ bị tấn công bởi nhiều hình thức tấn công được thiết kế để buộc hệ thống ML phạm lỗi có chủ ý. Kẻ tấn công có thể đầu độc tập dữ liệu đào tạo hoặc thiết kế ngược mã của mô hình. Bên cạnh đó, tin tặc có thể ‘brute-force’ mô hình ML với ‘adversarial AI’ được phát triển đặc biệt để tự động tạo ra nhiều mẫu tấn công cho đến khi phát hiện ra điểm yếu của mô hình. Tác động của các cuộc tấn công như vậy đối với các hệ thống chống phần mềm độc hại dựa trên ML có thể rất tàn khốc: một Trojan được xác định sai có nghĩa là hàng triệu thiết bị bị nhiễm và hàng triệu đô la bị mất.
Vì lý do này, một số cân nhắc chính cần được áp dụng cho việc sử dụng ML trong hệ thống bảo mật:
- Nhà cung cấp bảo mật nên hiểu và giải quyết cẩn thận các yêu cầu thiết yếu đối với hiệu suất ML trong thế giới thực, có thể là thù địch – các yêu cầu bao gồm sự mạnh mẽ đối với các đối thủ tiềm ẩn. Kiểm toán bảo mật dành riêng cho ML / AI và ‘nhóm đỏ’ phải là một thành phần quan trọng của sự phát triển ML / AI.
- Khi đánh giá tính bảo mật của giải pháp ML, nên đặt câu hỏi về mức độ phụ thuộc của giải pháp vào dữ liệu và kiến trúc của bên thứ ba, vì rất nhiều cuộc tấn công dựa trên đầu vào của bên thứ ba (chúng ta đang nói đến nguồn cấp dữ liệu thông minh về mối đe dọa, bộ dữ liệu công khai, trước mô hình ML được đào tạo và thuê ngoài).
- Các phương pháp ML không nên được xem như là “câu trả lời cuối cùng”. Chúng cần là một phần của phương pháp tiếp cận bảo mật nhiều lớp, nơi các công nghệ bảo vệ bổ sung và chuyên môn của con người cùng hoạt động, theo dõi nhau.
Vina Aspire là Công ty tư vấn, cung cấp các giải pháp, dịch vụ CNTT, An ninh mạng, bảo mật & an toàn thông tin tại Việt Nam. Đội ngũ của Vina Aspire gồm những chuyên gia, cộng tác viên giỏi, có trình độ, kinh nghiệm và uy tín cùng các nhà đầu tư, đối tác lớn trong và ngoài nước chung tay xây dựng.
Các Doanh nghiệp, tổ chức có nhu cầu liên hệ Công ty Vina Aspire theo thông tin sau:
Email: info@vina-aspire.com | Tel: +84 944 004 666 | Fax: +84 28 3535 0668 | Website: www.vina-aspire.com
![]()
Vina Aspire – Vững bảo mật, trọn niềm tin