Nhìn vào những vụ vi phạm và bê bối gần đây, không có gì lạ sao các tổ chức lại đánh giá cao các thông lệ quản trị và bảo mật dữ liệu tốt. Song, một khía cạnh của bảo mật dữ liệu và quản trị dữ liệu cho thấy khó nắm bắt.
Chắc chắn, các tổ chức có các giải pháp giám sát hoạt động dữ liệu (DAM), các công cụ phát hiện và phản hồi mở rộng (XDR), các chương trình quản trị do bộ phận pháp lý và SIEM của họ điều hành. Nhưng việc khám phá và phân loại dữ liệu nhạy cảm – đặc biệt là trong đám mây – đã được chứng minh là khó khăn.

Các giải pháp thường không đầy đủ. Chúng có thể phát hiện ra những cấu trúc dữ liệu nhưng chưa được cấu trúc hoặc dữ liệu ở phần còn lại nhưng không chuyển động. Thay vào đó, nhiều tổ chức đã sử dụng đến việc đẩy mạnh việc xác định dữ liệu nhạy cảm cho các chủ sở hữu doanh nghiệp. Trong những trường hợp cực đoan, các chuyên gia mà chúng tôi đã nói chuyện tại CISO ExecNet tuyên bố rằng “tôi không phải chịu trách nhiệm nếu dữ liệu nhạy cảm bị xâm phạm bởi chúng tôi mong chủ sở hữu của dữ liệu thực thi tuân thủ.”
Hiện nay, đây là một công việc cho chính chủ sở hữu dữ liệu ở một mức độ. Tuy nhiên, như một chuyên gia bảo mật đã hỏi chúng tôi, “Ai sẽ bị loại bỏ nếu một vi phạm được đưa ra?” Đó là một điều có căn cứ. Hãy cùng xem cách bảo mật và CNTT có thể hiểu rõ hơn về dữ liệu của họ.
Dữ liệu của bạn ở đâu?
Đầu tiên, hãy trả lời một số câu hỏi cơ bản. Ai thực sự sở hữu dữ liệu? Ai chịu trách nhiệm tối cao ? Có thể một nhóm bên ngoài CNTT sở hữu dữ liệu. ngay cả như vậy, bảo mật vẫn cần biết dữ liệu tồn tại ở đâu, di chuyển như thế nào và phải làm gì khi có sự cố.
Có vô số sai lầm nghiêm trọng để hiểu dữ liệu nhạy cảm. Làm cách nào để bạn có thể dễ dàng sử dụng dữ liệu để phát triển sản phẩm, xây dựng trải nghiệm khách hàng tốt hơn và tối ưu hóa quy trình kinh doanh?
Tuân thủ và Quyền riêng tư Yêu cầu Hiển thị
Đây không là một trường hợp sử dụng đáng kinh ngạc. Các quy định về tuân thủ và quyền riêng tư – từ quy định chung cho đến từng ngành cụ thể – không có dấu hiệu trì trệ. Quy định chung về bảo vệ dữ liệu, Đạo luật về quyền riêng tư của người tiêu dùng của California, Đạo luật về trách nhiệm giải trình và cung cấp bảo hiểm y tế và Đạo luật Sarbanes-Oxley chỉ là sự lựa chọn tổ hợp nhiều kí tự phúc tạp ngày càng tăng về các quy tắc và yêu cầu.
Hơn nữa, dữ liệu nhạy cảm không phải là một khối. Ví dụ, không đủ để biết rằng bộ phận bán hàng xử lý dữ liệu nhạy cảm. Điều đó không có nghĩa là các chính sách tuân thủ và các biện pháp bảo mật giống nhau được áp dụng cho mọi phần dữ liệu trong bộ phận đó.
Thông tin nhận dạng cá nhân, chẳng hạn như địa chỉ hoặc số điện thoại, khác với các giao dịch tài chính. Đến lượt nó, chúng khác với mật khẩu hoặc tên người dùng. Tùy theo quy định mà có thể có các quy định khác nhau đối với từng loại. Hơn nữa, những quy tắc đó có thể thay đổi tùy thuộc vào cách mọi người sử dụng dữ liệu đó và những người đó là ai.
‘Nâng cao’ thực sự có nghĩa là gì?
Một giải pháp hữu ích ở đây là khám phá nâng cao và phân loại dữ liệu nhạy cảm. Nhưng nâng cao có nghĩa là gì? Hãy xem xét cách tiếp cận hiện tại mà nhiều tổ chức thực hiện để đáp ứng các bước tuân thủ đầu tiên. Nó chủ yếu là thủ công. Thành công phụ thuộc vào các cuộc khảo sát về chủ sở hữu dữ liệu bộ phận, những người được mong đợi biết vị trí của từng phần dữ liệu nhạy cảm. Điều này rất tốn thời gian và có thể không chính xác và nhanh chóng lỗi thời.
Việc tuân thủ yêu cầu cả độ chính xác và đơn vị tiền tệ. Bạn cần biết bạn có dữ liệu nhạy cảm nào và chính xác vị trí của dữ liệu đó.
Để đạt được mục đích này, sự khám phá và phân loại nâng cao đã được tạo ra. Đó là một cách đáng tin cậy hơn để không chỉ khám phá mà còn hiểu dữ liệu nhạy cảm trong môi trường phân tán rộng rãi. Ví dụ: một giải pháp như IBM Security Discover and Classify có thể thực hiện điều này thông qua việc quét liên tục ở cấp nguồn dữ liệu và mạng, cùng với việc triển khai trí tuệ nhân tạo (AI) và máy học, để xử lý động từng phần dữ liệu. Điều này giúp các nhóm tuân thủ hiểu loại dữ liệu nào đang di chuyển trong nội bộ và cho các bên thứ ba. Rủi ro của bên thứ ba là một khía cạnh chính của nhiều nhiệm vụ tuân thủ.
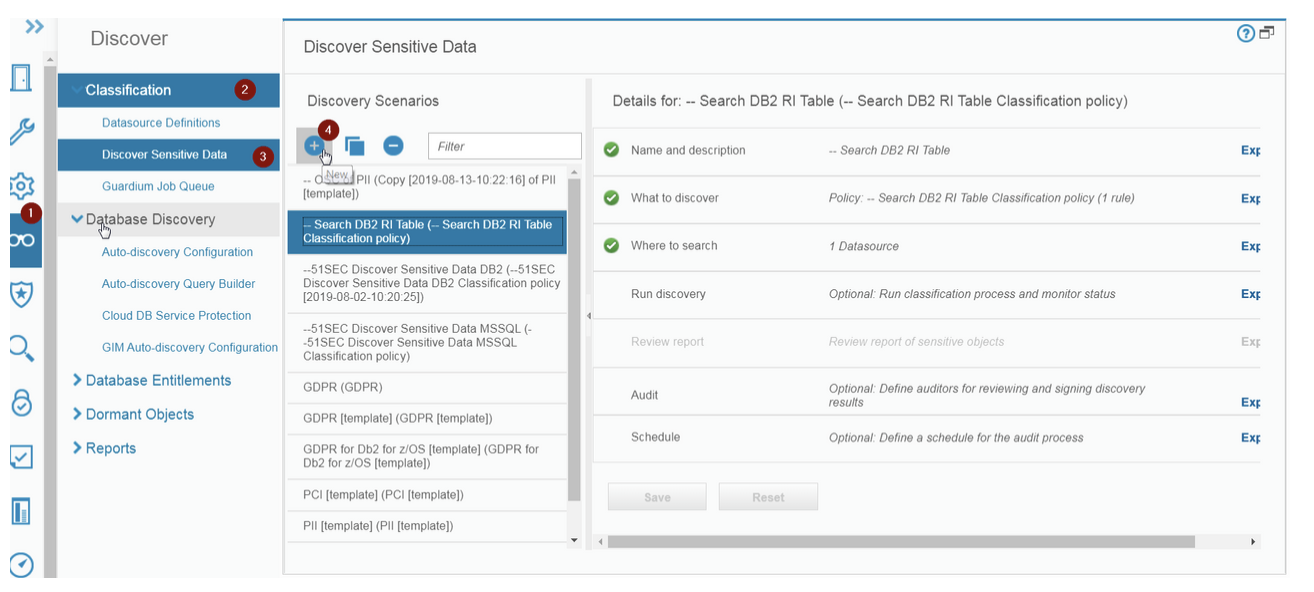
Khám phá và phân loại nâng cao cung cấp khả năng hiển thị để tạo ra các chính sách tuân thủ hiệu quả hơn. Sau đó, các chuyên gia bảo mật và tuân thủ có thể cải thiện tư thế tuân thủ của họ và nhanh chóng thích ứng khi các yêu cầu thay đổi.
Người tiêu dùng mong đợi xử lý dữ liệu tốt hơn
Không thiếu các nghiên cứu cho thấy rằng người tiêu dùng yêu cầu bảo mật dữ liệu tốt hơn từ các tổ chức xử lý dữ liệu cá nhân của họ. Các vi phạm lớn do các tác nhân độc hại bên ngoài gây ra có xu hướng đưa tin. Nhưng đó là kết quả của một chuỗi dài các điểm mù về quản trị và an ninh.
Một thách thức chung là làm thế nào để chia sẻ dữ liệu một cách an toàn. Các bộ phận khác nhau của doanh nghiệp thường duy trì các dữ liệu khác nhau. Các phòng ban này, vì mục đích bảo mật dữ liệu, thường hoạt động trong các hầm chứa.
Cách tiếp cận kín đáo này có thể mang lại niềm tin cho khách hàng rằng dữ liệu đang nằm trong tay tốt. Đồng thời, nó hạn chế khả năng của công ty đó trong việc sử dụng dữ liệu theo chức năng chéo. Vấn đề này quay trở lại một trong những trường hợp sử dụng kinh doanh được đề cập trước đó: xây dựng trải nghiệm khách hàng tốt hơn.
Chia sẻ dữ liệu dễ dàng hơn
Làm cách nào một tổ chức có thể bảo mật dữ liệu nhạy cảm cùng lúc với việc chia sẻ dữ liệu qua các ranh giới chức năng? Nhóm khách hàng thành công cần chia sẻ dữ liệu với nhóm sản phẩm. Đổi lại, họ phải chia sẻ dữ liệu với sự phát triển để cung cấp các sản phẩm và ứng dụng làm hài lòng khách hàng. Nhưng nếu ai đó xử lý sai dữ liệu dọc theo chuỗi đó, khách hàng sẽ không hài lòng. Việc khám phá và phân loại dữ liệu nâng cao một lần nữa chứng minh giá trị của chúng trong trường hợp này.
Các nguồn dữ liệu đã biết và chưa biết – cả nội bộ và bên ngoài – có thể được phát hiện để xác định dữ liệu nào đang được lưu trữ và xử lý bằng nhiều giải pháp hiện có trên thị trường. Sau khi dữ liệu được phát hiện, một giải pháp có thể được sử dụng để xây dựng bản đồ dữ liệu động nhằm giúp các nhóm trực quan hóa vị trí của dữ liệu nhạy cảm trong toàn tổ chức. Mức độ chi tiết này có nghĩa là khi dữ liệu được chia sẻ, sẽ dễ dàng hiểu được dữ liệu đã đi đâu, sử dụng như thế nào và cách tránh ‘cạn kiệt’ dữ liệu (tức là tệp nhật ký, tệp tạm thời và các mục khác không kém phần quan trọng nhưng được thường không được ghi lại hoặc theo dõi). Từ đó, các công cụ như DAM và XDR có thể giúp bảo mật dữ liệu trong ngôi nhà mới của nó khi dữ liệu lưu chuyển qua các phòng ban.
Xử lý thủ công Làm chậm phản hồi
Cả ba trường hợp sử dụng này đều có một luồng chung. Các phương pháp phân loại và khám phá dữ liệu hiện tại chủ yếu dựa vào các quy trình thủ công và sự tin cậy.
Mặc dù lòng tin là một nguồn tài nguyên vô giá, nhưng các quy trình thủ công không còn là chuẩn mực nữa. Thay vào đó, tự động hóa là rất quan trọng, do sự bùng nổ về khối lượng dữ liệu nhạy cảm mà các tổ chức thu thập, làm trầm trọng thêm tình trạng thiếu kỹ năng an ninh mạng, thời gian hạn chế để phản hồi những thứ như yêu cầu truy cập chủ thể dữ liệu (DSAR) và bối cảnh mối đe dọa dữ liệu ngày càng mở rộng.
Các tổ chức thường thiếu các công cụ và nguồn lực để đáp ứng các DSAR có mức độ ưu tiên cao trong khung thời gian dự kiến. Điều này có thể dẫn đến các hình phạt theo quy định. Nó cũng có thể tạo ra tâm lý tiêu cực của khách hàng nếu họ cảm thấy dữ liệu của họ không nằm trong tay an toàn.
Có một số chủ đề phổ biến trên ba trường hợp sử dụng này. Mỗi thứ bao gồm bảo vệ quyền riêng tư dữ liệu của khách hàng, tuân thủ các quy định phức tạp và mở khóa giá trị trong khối lượng dữ liệu. Vì vậy, hợp lý là các giải pháp tương tự nhau.
Một lần nữa, việc phát hiện và phân loại dữ liệu nâng cao có thể đạt được tốc độ mong đợi trong kịch bản DSAR. Tình huống này đòi hỏi sự kết hợp của quá trình quét liên tục để phát hiện ra dữ liệu nhạy cảm, AI để hiểu và ngữ cảnh hóa nó cũng như lập bản đồ dòng dữ liệu. Tất cả những thứ này làm việc cùng nhau để xây dựng một hồ sơ cho một chủ thể dữ liệu nhất định, tạo điều kiện cho phản hồi nhanh chóng, đầy đủ các yêu cầu.
Khám phá thêm
Đây chỉ là một mẫu nhỏ của các trường hợp sử dụng và chỉ là lời giải thích ngắn gọn về thế hệ tiếp theo của các công cụ phân loại và khám phá dữ liệu. Dữ liệu và nguồn dữ liệu sẽ tiếp tục nhân lên khi các tổ chức phát triển và chuyển đổi. Nhiều thách thức hơn sẽ phát sinh liên quan đến việc cố gắng xử lý dữ liệu nhạy cảm, tuân thủ và bảo mật dữ liệu. Nhưng đó là một nơi tuyệt vời để bắt đầu, đặc biệt là khi IBM Security và 1touch.io đang hợp tác trên công cụ IBM Security Discover và Classify.
IBM Security Discover và Classify tích hợp với IBM Security SOAR và IBM Security Guardium để hỗ trợ quyền riêng tư dữ liệu, phản ứng với mối đe dọa dữ liệu và các sáng kiến không tin cậy. Công cụ này là một bổ sung quan trọng, kịp thời cho dòng IBM Security. Để tìm hiểu thêm, hãy truy cập trang sản phẩm.
Vina Aspire là công ty tư vấn, cung cấp các giải pháp, dịch vụ CNTT, An ninh mạng, bảo mật & an toàn thông tin tại Việt Nam. Đội ngũ của Vina Aspire gồm những chuyên gia, cộng tác viên giỏi, có trình độ, kinh nghiệm và uy tín cùng các nhà đầu tư, đối tác lớn trong và ngoài nước chung tay xây dựng
Các Doanh nghiệp, tổ chức có nhu cầu liên hệ Công ty Vina Aspire theo thông tin sau:
Email: info@vina-aspire.com | Tel: +84 944 004 666
Fax: +84 28 3535 0668 | Website: www.vina-aspire.com
![]()
Vina Aspire – Vững bảo mật, trọn niềm tin